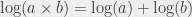Dans l’épisode précédent, j’ai expliqué deux manières de trier des livres et j’ai tenté de justifier combien de temps, en nombre d’opérations élémentaires, ça me prenait de faire ça, et j’ai évalué le nombre maximum d’opérations en fonction du nombre de livres que j’avais à trier.
Je suis arrivée aux conclusions suivantes :
- pour le « premier » tri, celui où je regarde à chaque étape où je dois mettre le livre suivant en parcourant tous les livres que j’ai mis jusqu’ici, j’ai, dans le meilleur des cas, 2n – 1 opérations, dans le pire des cas (n² + n)/2 opérations, et dans le cas moyen (n²+9n)/4 opérations.
- pour le « deuxième » tri, celui où je combine mes ensembles de livres deux par deux, j’ai, dans tous les cas, 2*n*log(n) opérations.
Je vais me permettre une petite courbe ici parce que les courbes c’est joli.
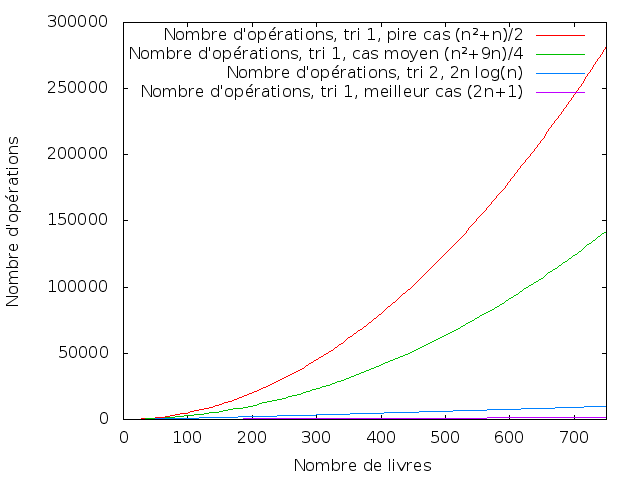
Au cas où j’aurais des daltoniens parmi mes lecteurs, les courbes sont, de haut en bas, dans l’ordre de la légende.
Cette histoire de « meilleur cas, pire cas, cas moyen » est très utilisée pour parler de la complexité des algorithmes. On ne s’intéresse en général que peu au « meilleur cas », parce qu’en général, Murphy aidant, c’est rarement le cas qui arrive. (Même si on peut éventuellement se poser la question de « comment faire pour avoir le meilleur cas plus souvent ? » si ça peut faire une différence pour l’algorithme.) En général, on s’intéresse plutôt au cas moyen et au pire cas.
L’avantage de s’intéresser au pire cas, c’est que c’est le seul qui fournit des garanties. Si je dis que mon algorithme, dans le pire cas, s’exécute en tant de temps, je garantis qu’il ne sera jamais plus long que ça, même s’il lui arrive d’être plus rapide. Dans certains cas, on a besoin de ce genre de garanties. En particulier, on s’intéresse parfois (dans le domaine de la cryptographie en particulier) à ce qu’il se passe si un « adversaire » me fournit les données comme il veut, et de préférence de manière à compliquer ma vie le plus possible. Et on veut des garanties sur le fait que ce qu’on fait fonctionne comme on veut que ça fonctionne, même quand on a un adversaire en face qui fait tout pour nous pourrir la vie. L’inconvénient, c’est qu’on surestime souvent le temps d’exécution « usuel » si on prend en compte le pire cas, et qu’on peut se retrouver à le surestimer de beaucoup.
L’avantage de s’intéresser au cas moyen, c’est justement qu’on a une idée de ce qui se passe « normalement ». (Je fais beaucoup de raccourcis et je dis probablement des choses qui ne sont pas vraies dans le cas général, mais dans l’idée c’est pas si délirant que ça). Ça donne aussi une idée de ce qui se passe si on répète l’algorithme plusieurs fois sur des données indépendantes ; le temps moyen d’une exécution sera quelque part entre le meilleur cas et le pire cas. L’autre avantage de s’intéresser au cas moyen, c’est qu’il y a parfois des manières « simples » d’éviter au maximum le pire cas. Par exemple, si j’ai un adversaire qui me donne les livres dans un ordre qui me pourrit mon algorithme, je peux « compenser » ça par le fait de mélanger moi-même les livres au début pour que la probabilité d’être dans un « mauvais » cas soit faible (et ne dépende pas de ce que me fournit mon adversaire). L’inconvénient, c’est évidemment qu’on n’a aucune garantie sur le temps « maximum » que prend un algorithme.
Évidemment, ce qu’on fait au final dépend de ce qu’on veut faire (fou, non ?).
Ceci étant posé, les complexités, en nombre d’opérations, que j’ai données précédemment (2n-1, (n²+n)/2, (n²+9n)/4, 2n log(n)) ne sont pas celles qu’on utilise en général. Si on me demande les résultats précédents, je réponds que les complexités sont, respectivement, « n » (ou « linéaire »), « n² » (ou « quadratique »), « n² » et « n log n ». Ça peut paraître extrêmement approximatif et peu précis et tout ce genre de choses, et je dois dire que les premières fois que j’ai vu ce genre d’approximations, ça m’a agacée au plus haut point. Bon, le fait que c’était en cours de physique avait probablement un rapport avec ça, mais, bon. Depuis, je trouve que c’est drôlement pratique et même que ça a du sens. Il faut savoir, déjà, que le fait que « ça a du sens » a une justification mathématique solide. Je ne vais pas la donner ici, parce que c’est très nettement au-dessus du niveau du billet que je suis en train de vouloir écrire. Pour les gens intéressés, qui lisent l’anglais, et qui ont pas peur des trucs du genre « limite en plus l’infini de blah », il y a http://en.wikipedia.org/wiki/Big_O_notation (ou son pendant en français, http://fr.wikipedia.org/wiki/Comparaison_asymptotique, mais je trouve la version anglaise plus claire).
Bon, sinon, j’ai au moins deux trucs à tenter de justifier ici. Attention, ce que je vais faire ici est très, très peu rigoureux. La première question est celle de ce qui arrive aux « petits » termes. L’idée, c’est que je ne garde que ce qui « compte » dans le fait que mon nombre d’opérations augmente avec le nombre d’éléments à trier. Par exemple, si j’ai 750 livres à trier, et que je veux faire ça avec mon premier algorithme, dans le cas « moyen », j’ai (n²+9n)/4 opérations, c’est à dire n²/4 + 9n/4. Pour 750 livres, ces deux « morceaux » valent, respectivement, 140625 et… 1687. Si j’ai 1000 livres à trier, je monte à 250000 et 2250. Le premier « morceau » de l’expression est beaucoup plus gros, et il grandit beaucoup plus vite. Si je veux estimer le temps que ça me prend, sans avoir besoin de trop de précision, je peux prendre le n²/4 et laisser tomber le 9n/4 – déjà pour 1000 livres, le nombre d’opérations du 9n/4 correspond à moins de 1% du total.
La deuxième question est plus compliqué (à mon sens) : pourquoi est-ce que je considère identiques « n² » et « n²/4 », « 2 n log n » et « n log n » ? Encore une fois, il y a une justification mathématique derrière tout ça, que je vais tenter d’éviter de vous infliger. Mais on peut tenter de le justifier aussi en faisant de grands moulinets. (Je ne suis pas très satisfaite de mes explications ici, mais je ne trouve pas mieux. Si un Gentil Lecteur a mieux, qu’il n’hésite pas à expliquer dans les commentaires 🙂 ).
L’idée, c’est qu’on ne s’intéresse pas nécessairement à un algorithme « tout seul », mais à comparer différents algorithmes. Et, en particulier, on s’intéresse à la comparaison dite « asymptotique », c’est à dire à ce qu’il se passe quand on a un très grand nombre d’éléments en entrée de l’algorithme (par exemple un très grand nombre de livres à trier). Et si j’ai un très grand nombre de livres à trier, j’aimerais autant que ça me prenne le moins de temps possible, et donc je cherche le « meilleur » algorithme, celui qui va le plus vite.
Pour que ça me prenne le moins de temps possible, j’ai deux solutions. Ou bien je réduis le temps que chaque opération prend, ou bien je réduis le nombre d’opérations lui-même. Je prends mon algorithme 1, qui fait n²/4 opérations, et mon algorithme 2, qui fait 2 n log n opérations pour n éléments. Supposons que j’aie un ordinateur qui fait une opération en une seconde, et que je veuille trier 100 éléments. Avec le premier algorithme, ça lui prendra environ 2500 secondes. Avec le deuxième algorithme, ça lui prendra environ 1328 secondes (parce que 2*100*log(100) est environ égal à 1328). Maintenant, supposons que j’aie un ordinateur vachement plus rapide sur lequel faire fonctionner mon premier algorithme. Au lieu de prendre une seconde, cet ordinateur est cinq fois plus rapide et il peut effectuer une opération en un cinquième de seconde (0.2 seconde). Du coup, je peux trier mes 100 éléments en 0.2*100²/4 = 500 secondes, ce qui est plus rapide que ce que je peux faire avec l’autre ordinateur. Youpi. Mais il y a évidemment deux bémols à ça. Le premier bémol, c’est que si je mets mon deuxième algorithme sur le deuxième ordinateur aussi, je peux trier mes éléments en 0.2*2*100*log(100) = 265 secondes. Bon, supposons que pour une raison bizarre le deuxième algorithme ne fonctionne pas sur le deuxième ordinateur et qu’il faille que je le garde sur le premier ordinateur. Mais le deuxième bémol, c’est que si j’ai maintenant 1000 éléments à trier et non plus 100, ça va me prendre, avec le premier algorithme sur l’ordinateur vachement plus rapide, 0.2*1000²/4 = 50000 secondes, et avec le deuxième algorithme sur l’ordinateur vachement plus lent, 2*1000*log(1000) = 19931 secondes.
Et c’est un peu l’idée qu’il y a derrière la suppression des « nombres multiplicateurs » dans mon évaluation de complexité. Si j’ai un algorithme qui s’exécute avec une complexité « dans les n² » et un algorithme qui s’exécute avec une complexité « dans les n log n », je peux mettre l’ordinateur le plus puissant que je veux derrière le premier algorithme, il y aura toujours un nombre d’éléments pour lequel mon deuxième algorithme, même sur une machine très lente, ira plus vite que le premier. Le nombre d’éléments peut être très grand si la première machine est très rapide et la deuxième très lente, mais, comme je m’intéresse à ce qu’il se passe avec de très grands nombres d’éléments, c’est pas très grave.
Donc, quand je parle de comparer deux algorithmes, il est beaucoup plus intéressant de voir que j’en ai un dont le temps d’exécution est en n log n et un en n², que de pinailler sur la constante (le nombre) qui va devant le n log n ou le n².
Évidemment, pour deux algorithmes en n², on peut se poser la question de la constante qui va devant. En pratique, ça se fait assez peu, parce qu’à moins d’avoir des choses extrêmement simples et carrées (et encore), suivant la manière dont on implémente les choses (avec un langage de programmation), déterminer ladite constante devient très difficile. Il faut aussi se poser la question, exactement, de ce qu’est une opération. Il y a des modèles « classiques » qui permettent de définir tout ça, mais relier ces modèles aux langages de programmation actuels doit tenir à peu près de l’utopie.
Bon, et en tant que « gens qui font de l’algorithme », qu’est-ce qui nous plaît bien, qu’est-ce qui commence à nous faire grimacer, et qu’est-ce qui nous fait courir à toute vitesse dans l’autre sens ? Je donne tout ça en fonction de la « taille » de l’entrée, n ; pour mon exemple de tri, c’est le nombre d’éléments à trier. Si je fais des opérations sur des graphes, la taille de l’entrée va typiquement être le nombre de sommets du graphe, parfois le nombre d’arcs.
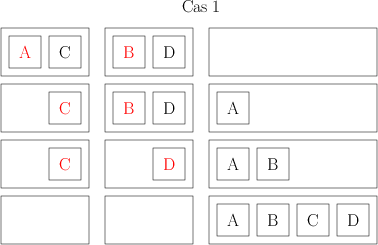
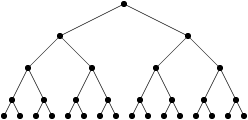
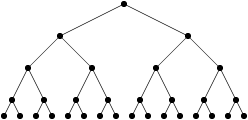
Les algorithmes « en temps constant » et « logarithmiques » (donc avec soit un nombre d’opérations constant, soit un nombre d’opération de type log n) sont relativement rares, parce qu’avec log n opérations (ou un nombre constant d’opérations), on n’a même pas le temps de regarder tout ce qu’on a en entrée. Donc, quand on trouve un algorithme de ce type, on est très très content. Un exemple « classique » d’algorithme qui fonctionne en temps logarithmique, c’est celui de chercher un élément dans une liste triée. Quand la liste est triée, on n’a pas besoin de lire toute la liste pour trouver l’élément qu’on cherche. On peut commencer par regarder s’il est avant ou après le milieu, regarder s’il est avant ou après le milieu de l’intervalle qu’on vient de redéfinir, et ainsi de suite. Je pourrais refaire une belle explication avec un arbre si ça vous intéresse, mais je vais pas faire ça maintenant.
On est aussi en général très content quand on trouve un algorithme linéaire (« n »). Ça veut dire, quelque part, qu’on lit tout ce qu’on a en entrée, on fait quelques opérations par élément, et paf c’est fini. n log n est aussi généralement considéré comme « acceptable ». C’est une borne importante, parce qu’on peut prouver que, dans les modèles algorithmiques courants (qui reviennent plus ou moins à compter des opérations « basiques »), on ne peut pas trier n éléments plus rapidement qu’en n log n opérations dans le cas général, c’est-à-dire sans rien savoir sur les éléments en question (Parce que si je sais qu’ils sont triés, ou dans l’ordre inverse, je peux les trier en temps linéaire). Du coup, il y a un certain nombre d’algorithmes qui s’appuient, à un moment ou un autre, sur un tri ; si on ne peut pas se débarrasser du tri, on ne peut pas non plus descendre en-dessous de n log n.
On commence à grommeler un peu à partir de n², n³, et à grommeler beaucoup sur les puissances supérieures de n. Les algorithmes qui peuvent s’exécuter en un temps 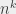



Évidemment, en pratique, ce genre de raisonnement a ses limites aussi. J’ai un exemple qui m’amuse personnellement beaucoup, et j’espère qu’il vous amusera aussi. Considérons le problème de la multiplication de deux matrices entre elles. (Pour les gens qui n’ont pas jamais vu de matrices, on peut voir une matrice comme un tableau de nombres – et il se trouve qu’on peut multiplier ces tableaux de nombres. C’est un peu plus compliqué que de multiplier les nombres un par un, mais guère.) (Dit la fille qui savait pas comment multiplier deux matrices avant la 3e année d’école d’ingénieur, mais c’est une autre histoire.)
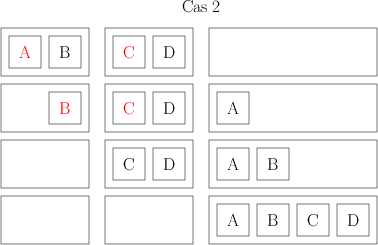
L’algorithme qu’on apprend à l’école permet de multiplier deux matrices en un temps n³, où on considère des matrices de taille n*n (pour les gens pas familiers des matrices : on trace un tableau de n lignes et n colonnes, et on met des nombres dedans). En se forçant un peu, on peut trouver un algorithme (algorithme de Strassen, de son petit nom), pas trop compliqué, qui fonctionne en un temps 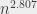
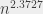
Voilà, sur cette anecdote amusante, je vais arrêter là pour ce billet. J’espère que c’était approximativement compréhensible, ce dont je ne suis pas vraiment sûre. N’hésitez pas à poser des questions, faire des remarques et tout ce genre de choses 🙂
 , où
, où 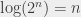

 . Et, bon, ben de la même manière, je peux définir un logarithme qui soit la réciproque de ce
. Et, bon, ben de la même manière, je peux définir un logarithme qui soit la réciproque de ce 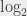 ,
, 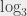
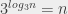

 ,
,  (parce que
(parce que  ); tous les nombres entre 10 et 100 ont un logarithme en base 10 entre 1 et 2. De la même manière, on peut estimer que le logarithme en base 10 de 14578 est entre 4 et 5. Pour voir ça, il suffit de voir que 14578 est compris entre
); tous les nombres entre 10 et 100 ont un logarithme en base 10 entre 1 et 2. De la même manière, on peut estimer que le logarithme en base 10 de 14578 est entre 4 et 5. Pour voir ça, il suffit de voir que 14578 est compris entre  et
et  , ce qui permet de conclure sur la valeur du logarithme. (Je passe un certain nombre de choses sous le tapis ici, en particulier les raisons qui font qu’on peut effectivement conclure ça.)
, ce qui permet de conclure sur la valeur du logarithme. (Je passe un certain nombre de choses sous le tapis ici, en particulier les raisons qui font qu’on peut effectivement conclure ça.) (qui correspond à la puissance à laquelle j’élève
(qui correspond à la puissance à laquelle j’élève 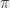 (qui correspond à… bon, ça ira, peut-être) si ça me chante. C’est moins « intuitif » si je considère mon explication avec les arbres et le nombre de niveaux (parce que c’est difficile de faire
(qui correspond à… bon, ça ira, peut-être) si ça me chante. C’est moins « intuitif » si je considère mon explication avec les arbres et le nombre de niveaux (parce que c’est difficile de faire  . Le logarithme népérien est un logarithme en base
. Le logarithme népérien est un logarithme en base  . On peut exprimer n’importe quel logarithme dans n’importe quelle base
. On peut exprimer n’importe quel logarithme dans n’importe quelle base  comme ceci :
comme ceci :
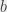 comme ça :
comme ça :

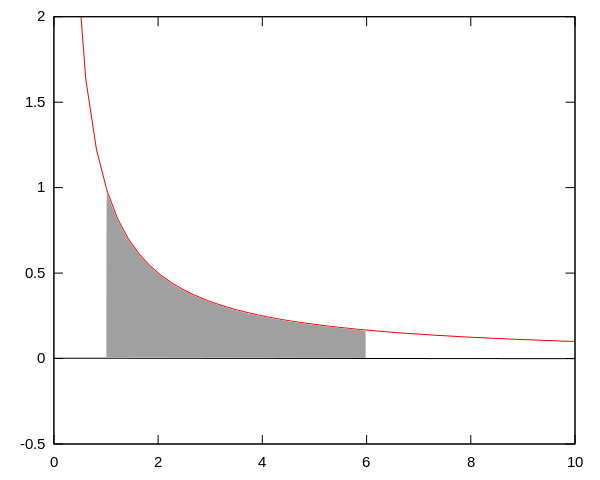
 . La zone grise correspond ici à l’intégrale de 1 à 6 ; l’aire de cette zone est égale à ln(6). Et on peut représenter le logarithme népérien de n’importe quelle valeur (supérieure à 1) par l’aire de la surface située entre l’axe des
. La zone grise correspond ici à l’intégrale de 1 à 6 ; l’aire de cette zone est égale à ln(6). Et on peut représenter le logarithme népérien de n’importe quelle valeur (supérieure à 1) par l’aire de la surface située entre l’axe des  et la courbe
et la courbe