Je viens de me rendre compte que j’avais pas encore parlé de théorie de Ramsey dans ce blog, ce qui est profondément scandaleux, parce que c’est un sujet très rigolo. Donc, commençons – aujourd’hui, c’est TPA.
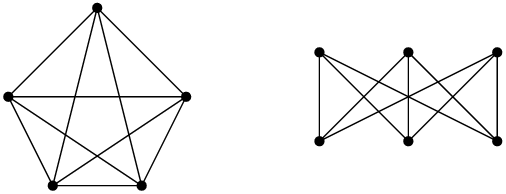
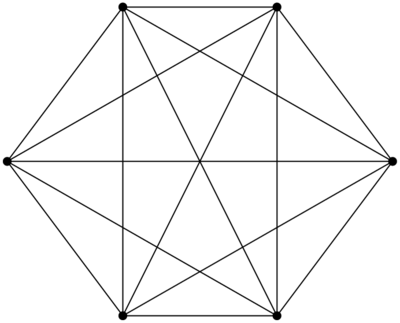
Supposons que nous ayons un graphe dit « complet », c’est-à-dire qu’on se donne un ensemble de sommets, et qu’on trace tous les arcs possibles entre tous les sommets. On dénote par 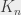 le graphe complet sur n sommets - par exemple, je vous présente
le graphe complet sur n sommets - par exemple, je vous présente  :
:

Maintenant, on va colorier les arcs du graphe en rouge et en bleu, de façon arbitraire. On peut par exemple colorier tous les arcs en bleus, tous les arcs en rouge, ou choisir d’autres coloriages :

Et avec ce coloriage, on se pose une première question : est-ce qu’il est possible d’avoir un coloriage tel qu’on ne puisse pas trouver dans la figure un triangle bleu ou un triangle rouge, c’est-à-dire trois sommets reliés uniquement par des arcs bleus ou rouges ? Les deux du haut ne fonctionnent clairement pas (puisque tous les sommets sont reliés par des arcs bleus et rouges respectivement). Le coloriage en bas à gauche ne fonctionne pas non plus : il a un triangle bleu et un triangle rouge (vous les voyez ?). Le coloriage en bas à droite n’a pas de triangle rouge, mais il a un triangle bleu.
Pour 5 points, ce n’est pas très difficile de finir par trouver un coloriage qui ne contient ni triangle bleu ni triangle rouge, et c’est celui-ci :

L’étape suivante est de se poser la même question non pas avec un graphe complet sur 5 sommets () mais avec un graphe complet sur 6 sommets (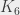 ), comme celui-ci :
), comme celui-ci :

Et la réponse est non, ce n’est pas possible : on ne peut pas colorier une avec deux couleurs en évitant d’avoir un triangle monochromatique (tout bleu ou tout rouge, donc). La première remarque qu’on peut faire, c’est que pour vérifier par force brute que c’est effectivement le cas, ça va prendre un petit peu de temps. Le graphe ci-dessus a 15 arcs, ce qui correspond à  coloriages différents. Pour voir ça, on peut choisir un ordre pour les arcs (n’importe quel ordre) et commencer à colorier. Pour le premier arc, on peut choisir rouge ou bleu, ça fait deux choix. Pour le deuxième arc, idem – et on a déjà quatre choix avec deux arcs, puisqu’ils peuvent être tous les deux rouges, tous les deux bleus, rouge-bleu ou bleu-rouge. Le troisième choix multiplie encore ces choix par deux (puisque chaque choix peut correspondre à un troisième arc rouge ou bleu), et ainsi de suite pour les 15 arcs, soit 2×2×2×…×2 = . , ça fait 32768. À la main, ça va faire beaucoup de coloriages à vérifier, mais sur un ordinateur, ça reste encore nettement dans le domaine du faisable.
coloriages différents. Pour voir ça, on peut choisir un ordre pour les arcs (n’importe quel ordre) et commencer à colorier. Pour le premier arc, on peut choisir rouge ou bleu, ça fait deux choix. Pour le deuxième arc, idem – et on a déjà quatre choix avec deux arcs, puisqu’ils peuvent être tous les deux rouges, tous les deux bleus, rouge-bleu ou bleu-rouge. Le troisième choix multiplie encore ces choix par deux (puisque chaque choix peut correspondre à un troisième arc rouge ou bleu), et ainsi de suite pour les 15 arcs, soit 2×2×2×…×2 = . , ça fait 32768. À la main, ça va faire beaucoup de coloriages à vérifier, mais sur un ordinateur, ça reste encore nettement dans le domaine du faisable.
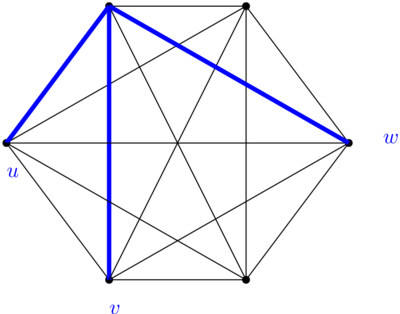
Avant de programmer le coloriage et de vérifier, on peut se demander s’il y aurait moyen de prouver qu’il y a toujours un triangle monochromatique dans une coloriée avec 2 couleurs. Donc, on prend un coloriage, n’importe lequel. On prend un sommet, n’importe lequel aussi. Ce sommet, il a 5 arcs qui y sont connectés, et parmi ces cinq arcs, il y en a au moins trois qui sont de la même couleur (parce que si j’ai au plus deux arcs bleus ET au plus deux arcs rouges, ben j’ai au plus 4 arcs). Pour faire simple, je vais supposer que les trois arcs qui sont de la même couleur sont bleus (je peux toujours faire ça, si ce n’est pas le cas il suffit de remplacer rouge par bleu et bleu par rouge dans ce qui suit). Maintenant on fait une petite figure avec des notations.

J’ai au moins trois arcs bleus qui partent de mon sommet initial, j’en choisis exactement trois (les deux autres peuvent être rouges ou bleus). Ces arcs définissent trois points sur le graphe, qui sont les autres extrémités des trois arcs ; je nomme ces points  et
et 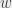 . Et là, il peut se passer plusieurs choses. Si l’arc entre
. Et là, il peut se passer plusieurs choses. Si l’arc entre  et
et  est bleu, alors j’ai un triangle bleu. Si l’arc entre et est bleu, alors j’ai un triangle bleu. Si l’arc entre et est bleu, alors j’ai un triangle bleu. Et si rien de tout ça ne se passe…
est bleu, alors j’ai un triangle bleu. Si l’arc entre et est bleu, alors j’ai un triangle bleu. Si l’arc entre et est bleu, alors j’ai un triangle bleu. Et si rien de tout ça ne se passe…

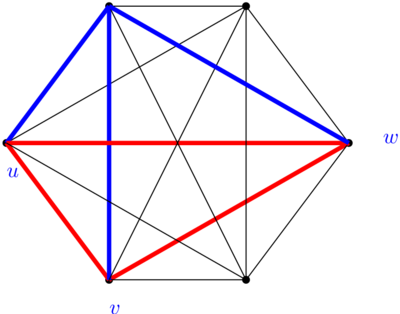
ben l’arc entre et est rouge, l’arc entre et est rouge, et l’arc entre et est rouge aussi, donc le triangle défini par  est tout rouge. Tout ce que j’ai raconté là s’applique à n’importe quel coloriage (même s’il faut éventuellement changer rouge en bleu et bleu en rouge), et donc on ne peut pas trouver de coloriage qui n’ait ni triangle bleu, ni triangle rouge.
est tout rouge. Tout ce que j’ai raconté là s’applique à n’importe quel coloriage (même s’il faut éventuellement changer rouge en bleu et bleu en rouge), et donc on ne peut pas trouver de coloriage qui n’ait ni triangle bleu, ni triangle rouge.
La remarque suivante, c’est que n’importe quelle (c’est-à-dire un graphe complet sur  sommets), pour
sommets), pour  , contient une . Donc si on ne peut pas colorier une sans avoir de triangle monochromatique, on ne peut pas non plus colorier une
, contient une . Donc si on ne peut pas colorier une sans avoir de triangle monochromatique, on ne peut pas non plus colorier une 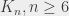 sans triangle monochromatique.
sans triangle monochromatique.
Donc, pour les triangles, on sait ce qu’il se passe : pour  , on peut trouver un coloriage tel qu’on ne trouve pas de triangle monochromatique, et pour , on a prouvé qu’il n’existait pas.
, on peut trouver un coloriage tel qu’on ne trouve pas de triangle monochromatique, et pour , on a prouvé qu’il n’existait pas.
La question suivante est : maintenant qu’on a des choses pour les triangles, est-ce qu’on peut avoir le même genre de résultat pour plus de points ? Plus spécifiquement, si je considère une , est-ce que je peux la colorier avec deux couleurs de manière à éviter d’y trouver une  , , ,
, , , 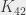 de la même couleur (remarquons qu’un triangle est une
de la même couleur (remarquons qu’un triangle est une  😉 )? Et ben, c’est une question compliquée. Pour être sûr de trouver une , il a été prouvé qu’on a besoin de 18 points. Ce qui veut dire qu’on peut colorier ce bidule-là avec 2 couleurs et ne pas y trouver de monochromatique:
😉 )? Et ben, c’est une question compliquée. Pour être sûr de trouver une , il a été prouvé qu’on a besoin de 18 points. Ce qui veut dire qu’on peut colorier ce bidule-là avec 2 couleurs et ne pas y trouver de monochromatique:

Si on rajoute un sommet et qu’on le connecte à tous les autres, par contre, on est sûr de trouver une monochromatique si on colorie avec deux couleurs. Là, pour le coup, si on veut réellement vérifier tous les coloriages possibles, il va vraiment falloir faire des progrès sur la puissance informatique. Une  (un graphe complet sur 18 sommets, donc) a 153 arcs, donc si on se mettait en tête de vérifier tous les coloriages, il faudrait en vérifier
(un graphe complet sur 18 sommets, donc) a 153 arcs, donc si on se mettait en tête de vérifier tous les coloriages, il faudrait en vérifier  . Si on est capable de vérifier un coloriage par nanoseconde (ce qui n’est pas franchement réaliste), il faudrait plus de 3 000 000 000 000 000 000 000 000 000 (3 suivi de 27 zéros) SIÈCLES pour tout vérifier… on est pas rendu 🙂
. Si on est capable de vérifier un coloriage par nanoseconde (ce qui n’est pas franchement réaliste), il faudrait plus de 3 000 000 000 000 000 000 000 000 000 (3 suivi de 27 zéros) SIÈCLES pour tout vérifier… on est pas rendu 🙂
Là où ça devient VRAIMENT amusant, c’est quand on se pose la question de trouver des et supérieur (qui soient monochromatiques, donc). Pour la , on sait que pour plus de 49 sommets, on la trouvera nécessairement. On sait aussi qu’on peut construire un coloriage sur 42 sommets sans monochromatique. Le lecteur attentif aura remarqué qu’on ne sait pas ce qu’il se passe entre 43 et 49 sommets… La situation est de moins en moins claire au fur et à mesure : pour la 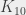 monochromatique, on sait que le seuil se situe quelque part entre 798 (pour 797 sommets on sait qu’on peut colorier sans avoir de monochromatique) et… 23556 (pour un graphe complet sur 23556 sommets colorié avec deux couleurs, on sait qu’on aura toujours une monochromatique).
monochromatique, on sait que le seuil se situe quelque part entre 798 (pour 797 sommets on sait qu’on peut colorier sans avoir de monochromatique) et… 23556 (pour un graphe complet sur 23556 sommets colorié avec deux couleurs, on sait qu’on aura toujours une monochromatique).
Le théorème de Ramsey qui donne son nom à ce billet de blog dit que quelque soit  , on peut trouver un tel que tout coloriage avec deux couleurs d’une contienne nécessairement une
, on peut trouver un tel que tout coloriage avec deux couleurs d’une contienne nécessairement une 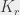 monochromatique. Ledit théorème est plus général que ça : il dit que pour tout
monochromatique. Ledit théorème est plus général que ça : il dit que pour tout  on peut trouver un tel que tout coloriage de avec
on peut trouver un tel que tout coloriage de avec  couleurs
couleurs 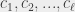 contient ou bien une
contient ou bien une  de couleur
de couleur  , ou bien une
, ou bien une 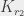 de couleur
de couleur  , …, ou bien une
, …, ou bien une  de couleur
de couleur  . Et on dénote par
. Et on dénote par  . (Pour rattacher aux trucs précédents, j’ai démontré que
. (Pour rattacher aux trucs précédents, j’ai démontré que  , et j’ai indiqué que
, et j’ai indiqué que  ,
,  et que
et que 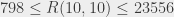 .
.
On peut exprimer ça de façon plus « philosophique » en disant qu’une structure suffisamment grande aura toujours un peu d’ordre local quelque part. Ce que je trouve personnellement assez fascinant.
Le mot de la fin revient à Joel Spencer: « Erdős nous a demandé d’imaginer une force d’extraterrestres, beaucoup plus puissante que nous, qui atterrit sur Terre et nous demande la valeur de R(5,5), ou bien ils détruisent la planète. Dans ce cas, dit-il, nous devrions combiner la puissance de tous nos ordinateurs et de tous nos mathématiciens pour tenter de trouver la valeur. Mais supposons qu’ils demandent R(6,6). Dans ce cas, il pense qu’il faudrait détruire les extraterrestres. » (traduction personnelle).



 , et j’ai des formules qui sont de ce type:
, et j’ai des formules qui sont de ce type:
 à
à 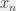 (on parle d’une affectation) qui permettent d’évaluer la formule à 1 (on dit alors que la formule est satisfaite). Dans le cas général, c’est un problème
(on parle d’une affectation) qui permettent d’évaluer la formule à 1 (on dit alors que la formule est satisfaite). Dans le cas général, c’est un problème  – parce que pour chaque variable, j’ai deux possibilités, 0 ou 1. Donc la probabilité de succès de cet algorithme, si j’ai
– parce que pour chaque variable, j’ai deux possibilités, 0 ou 1. Donc la probabilité de succès de cet algorithme, si j’ai  : parmi les
: parmi les  . Si j’ai choisi pour
. Si j’ai choisi pour  la valeur 0, il est « trivialement idiot » de choisir 0 pour
la valeur 0, il est « trivialement idiot » de choisir 0 pour 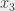 puisque je n’ai alors aucune chance de satisfaire la formule. Donc par « trivialement idiot », je veux dire qu’il y a une clause qu’il n’y a plus qu’une seule chance de satisfaire, c’est-à-dire qu’on a déjà affecté des valeurs à deux variables sur les trois de la clause, et que la clause n’est toujours pas satisfaite. Si j’utilise mon algorithme précédent, j’ai une probabilité 7/8 de trouver une affectation satisfaisante (parce qu’avec probabilité 1/8 je tombe sur 000 pour mes variables et ma formule n’est pas satisfaite). Si j’essaie d’éviter les trucs trivialement idiots… ben déroulons le truc. Je commence par
puisque je n’ai alors aucune chance de satisfaire la formule. Donc par « trivialement idiot », je veux dire qu’il y a une clause qu’il n’y a plus qu’une seule chance de satisfaire, c’est-à-dire qu’on a déjà affecté des valeurs à deux variables sur les trois de la clause, et que la clause n’est toujours pas satisfaite. Si j’utilise mon algorithme précédent, j’ai une probabilité 7/8 de trouver une affectation satisfaisante (parce qu’avec probabilité 1/8 je tombe sur 000 pour mes variables et ma formule n’est pas satisfaite). Si j’essaie d’éviter les trucs trivialement idiots… ben déroulons le truc. Je commence par 
 et
et  . Avec mon algorithme « simple », la probabilité de succès est de 2/8 = 1/4. Avec mon algorithme qui cherche à éviter les trucs « trivialement idiots »… aussi, dans certaines conditions. Si je commence par la variable
. Avec mon algorithme « simple », la probabilité de succès est de 2/8 = 1/4. Avec mon algorithme qui cherche à éviter les trucs « trivialement idiots »… aussi, dans certaines conditions. Si je commence par la variable  … Pour la première variable,
… Pour la première variable,  ou la clause
ou la clause 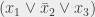 (selon la valeur affectée à
(selon la valeur affectée à  sur
sur  , si
, si  est trivialement idiot, on affecte 1 à
est trivialement idiot, on affecte 1 à  est trivialement idiot, on affecte 0 à
est trivialement idiot, on affecte 0 à  et une clause
et une clause  , donc quelque part c’est AUSSI trivialement idiot de mettre
, donc quelque part c’est AUSSI trivialement idiot de mettre  -SAT
-SAT , où
, où 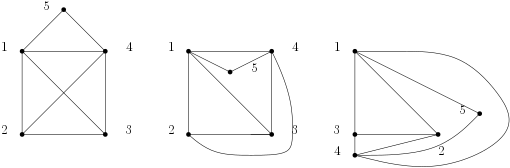
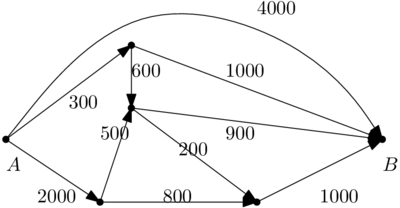
 . En voici des représentations dans le plan ; comme on l’a vu, ces représentations ne sont pas uniques, mais vous pouvez chercher longtemps avant de trouver une représentation où deux arcs ne se croisent pas.
. En voici des représentations dans le plan ; comme on l’a vu, ces représentations ne sont pas uniques, mais vous pouvez chercher longtemps avant de trouver une représentation où deux arcs ne se croisent pas.