Note : ce billet a été écrit AVANT mon passage du TOEFL et a pour base le matériau de préparation que j’ai sous la main. J’essaierai de le mettre à jour ou de faire un billet sur les conditions précises de l’examen… quand je l’aurai passé 🙂
Mise à jour : j’ai publié un deuxième billet intitulé « TOEFL, résultat des courses » avec les impressions post-examen.
J’ai appris avec une joie non dissimulée (ahem) qu’il fallait que je passe un examen d’anglais (on me laisse le choix entre l’IELTS, le TOEFL et le CAE) pour attester d’un niveau C1 d’ici au 18 septembre, début des cours de master à l’ETH.
J’ai déjà passé l’IELTS il y a 10 ans et c’était chiant. Il n’est plus valide parce que ces machins sont valides que deux ans – c’est une rente… Je PEUX comprendre la justification de refaire certifier « régulièrement » si nécessaire. Évidemment, le niveau en langues évolue avec le temps. Mais bon, par exemple, à titre personnel, j’ai beaucoup plus l’occasion de pratiquer mon anglais que, disons, ma conduite automobile. Mon permis de conduire est valable à vie, ma certif d’anglais non. Et pourtant… je risque nettement moins, disons, de tuer quelqu’un avec mon niveau d’anglais. Je crois que je garde mon argument précédent : c’est une rente 🙂
Bref, plutôt par défaut qu’autre chose, je me suis inscrite au TOEFL pour dans deux semaines (et demie). Du coup, je potasse l’examen ; je SAIS que j’ai un niveau d’anglais suffisant pour justifier un C1, mais encore faut il arriver à le faire certifier sur un test qui a ses propres aléas. Et il me faut 100 points sur 120, ce qui est plutôt élevé.
Le TOEFL, de nos jours, est surtout passé dans sa version dite « iBT » (Internet Based Test) – qu’il faut quand même aller passer dans un centre d’examen évidemment – est noté sur 120 points, 30 points par section : compréhension écrite, compréhension orale, expression écrite, expression orale. Donc, en moyenne, il faut que je fasse 25 points sur 30 dans les quatre catégories.
Compréhension écrite
3 à 4 textes d’environ 700 mots à lire, et 36 à 56 questions auxquelles répondre. Les textes sont de type « académique » dans divers domaines qui vont de l’histoire de l’art à la biologie. Après avoir jeté un œil à quelques examens type, je sais qu’il va falloir que je fasse très attention là : les questions sont souvent ambiguës, parfois carrément traîtres. Par contre, la bonne nouvelle, c’est que je viens de voir qu’il y avait plus de questions que de points ; je pensais avoir « droit » à 5 erreurs sur 30 questions pour valider le 25, mais en fait j’ai « droit » à plus d’erreurs que ça. (Plus de questions où se bananer aussi, évidemment, mais j’estime que le nombre de bananages est raisonnablement constant, donc j’augmente ma note si le nombre de questions augmente. Quoi, ça marche pas comme ça ?)
Compréhension orale
De ce que j’ai vu, 6 bandes audio qui varient du « j’ai peur de pas avoir assez de sous pour aller à l’université, qu’est-ce que je peux faire ? » à l’extrait de cours sur n’importe quel sujet académique, et en tout 34 à 51 questions (donc, pareil que pour la compréhension écrite, c’est mis à l’échelle).
De manière générale, J’AIME PAS les tests de compréhension orale. Déjà parce que, de mon point de vue, ils tiennent plus de tests de mémoire/prise de note du bon détail au bon moment que de tests de… ben de compréhension orale, quoi. C’est évidemment particulièrement le cas si les questions ne sont pas données avant la lecture de la bande audio, ce qui est le cas pour le TOEFL.
Et là, mon problème, c’est que je suis pas très douée en prise de notes. Enfin, plus spécifiquement, je suis pas très douée en prise de notes sur un support oral uniquement. S’il y a des slides, un tableau, bref, des trucs comme il y a dans la vraie vie dans la majeure partie des cours et des conférences, ça va plutôt mieux, mais support oral uniquement, j’ai du mal à ne pas perdre le fil. Là où c’est « drôle », c’est qu’en pratique, la seule situation où je me retrouve dans ce genre de cas de « prise de notes à l’oral uniquement », c’est… les tests de compréhension orale en langues. C’est probablement pour ça que je déteste l’exercice qui me paraît probablement le plus artificiel et pénible. Et peut-être le plus aléatoire, aussi. Ce qui est con, parce que j’ai vraiment aucun problème sur le contenu des bandes audio en général.
Expression orale
6 questions, auxquelles il faut répondre en 45 à 60 secondes selon la question. Deux types de questions : deux questions « bateau », heu, pardon, « independent questions » et quatre questions « integrated » : deux « listening/reading/speaking » et deux « listening/speaking ».
La première question demande une description d’un truc « personnel » (thème allant des vacances idéales au prof préféré).
La deuxième propose deux alternatives sur une situation donnée et demande une réponse argumentée sur ce qu’on préfère (« je m’en fous » n’étant probablement pas une réponse valide).
La troisième affiche un petit texte et fait écouter une conversation ; de manière générale le thème tourne autour des réglements ou procédures universitaires, et il faut résumer la position d’une des personnes qui cause et les raisons pour lesquelles la personne en question a l’opinion en question.
La quatrième question porte sur un sujet académique et, là encore, ya un petit texte suivi d’une bande audio, et une question derrière (« expliquez pourquoi, au vu du texte, ce que le prof raconte semble avoir un sens »).
La question 5 passe une bande audio de gens qui causent d’un souci universitaire quelconque, proposent deux solutions, et la tâche est de décrire la situation et d’expliquer ce qui nous paraît la meilleure solution.
La sixième question joue d’abord un extrait de cours dans un domaine quelconque et pose ensuite une question sur le contenu de l’extrait en question (donner les points majeurs, résumer, ce genre de choses).
De manière générale, c’est probablement sur cette partie (la partie orale dans son ensemble) qu’il faut que je bosse le plus : m’entraîner à avoir une opinion sur les trucs dont je me fous 😉 (heu, ça, ça fait 30 ans, c’est pas gagné…), avoir une idée de ce que j’ai le temps de dire en 45 et en 60 secondes, éventuellement préparer quelques trucs pour les sujets « bateau ».
Expression écrite
2 textes à rédiger : une « integrated task » et une « independent writing task ».
L’integrated présente un texte académique, un bout de cours oral, et demande de faire la relation entre les deux, éventuellement de contrer l’un avec l’autre.
L’independent est un « Est-ce que vous êtes d’accord avec l’énoncé suivant », ce à quoi bien évidemment ma première réponse instinctive est « Bin, ça dépend… » et/ou « Oui enfin c’est ptêt un peu plus subtil que ça… » – bref, il va peut-être falloir que je m’entraîne un peu sur des sujets blancs là aussi 🙂 20 minutes pour la première question, 30 pour la deuxième question, et ils attendent apparemment de l’ordre de 300 mots par réponse.
Ça me fait plutôt moins peur que la partie orale, parce qu’au moins il y a le temps de penser, de corriger et de rectifier, c’est pas du « one shot », c’est plus confortable en ce qui me concerne. Ça reste relativement court pour pondre 300 mots, mais ça devrait tout de même aller.
Et le pire de tout sur ce truc là, c’est qu’il faut passer l’expression écrite sur un clavier QWERTY. Et que donc… ben va falloir que je me remette au QWERTY. Et à regarder mon clavier et pas mon écran. Et ça, ÇA, ça fait vraiment chier.




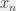





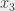





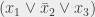
sur
, si
est trivialement idiot, on affecte 1 à
est trivialement idiot, on affecte 0 à




