Tiens, ça fait longtemps que j’ai pas causé de maths ici. Il y a eu des actualités intéressantes très récemment, alors je vais en parler un peu, en espérant pas dire trop de bêtises parce que ça commence à toucher à des trucs que je maîtrise moins 🙂
Il y a à peu près un an, László Babai, mathématicien-avec-une-bonne-dose-d’informaticien a fait l’équivalent des (très) gros titres dans le monde de l’informatique théorique avec un article intitulé Graph Isomorphism in Quasipolynomial Time ou, en français, « Isomorphisme de graphes en temps quasipolynomial » (Je vais citer Langelot Pickpocket : « C’est très facile d’écrire l’anglais. Il n’y a qu’à renverser l’ordre des noms et des adjectifs. »). Il y a quelques jours, le même László Babai a publié sur son blog un « oops, en fait ça passe pas » (c’est-à-dire une rétractation partielle du papier, il y avait une erreur dans l’analyse qui ne permettait pas de conclure à un temps quasi-polynomial). Aujourd’hui, alors même que je retournais voir cette page pour ajouter un lien vers mon blog, je vois que le temps quasi-polynomial est de nouveau sur le tapis ! C’est plus palpitant que Game of Thrones, cette histoire 😉
Bon, là, normalement, j’ai perdu mes trois lecteurs. Snif. Revenez, les gens, jvais expliquer un peu de quoi on cause… D’abord, petite question : est-ce que ces deux graphes sont identiques ?
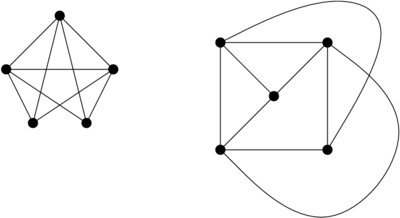
Normalement, c’est le moment où vous me dites « ben, ça dépend… ça veut dire quoi, identique ? » – ce à quoi je réponds « ben, ça dépend de la définition qu’on choisit, en fait ».
J’utilise ici le terme « identique » pour dire « isomorphe », ce qui est un abus de langage mais un que je m’autorise. Isomorphe, c’est un mot blindé de grec, comme l’indique le « ph » (ouais, je fais de l’approximation liguistique aussi) : préfixe « iso » – même, et « morphe » – forme. Donc, « graphes isomorphes » : graphes qui ont la même tête. Là, j’en ai deux qui se disent « elle se paye ma fiole », parce que les deux graphes ci-dessus, ils ont pas vraiment la même tête, à froid comme ça.
Mais si je les affiche comme ça, est-ce que c’est mieux ?
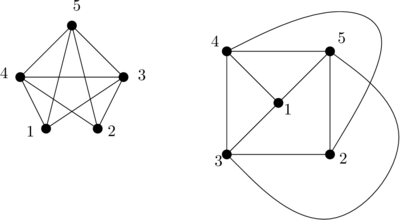
Avec des petits numéros, je peux dire que :
- 1 est relié à 3, 4 et 5
- 2 est relié à 3,4 et 5
- 3 est relié à 1, 2, 4 et 5
- 4 est relié à 1, 2, 3 et 5
- 5 est relié à 1, 2, 3 et 4
et ce sur les deux graphes. C’est ce qu’on entend par « isomorphisme de graphe » : on peut associer chaque sommet du premier graphe à un sommet du deuxième graphe de sorte que si les sommets 

Il existe des cas où la réponse est « les deux graphes ne sont pas isomorphes » de manière immédiate. Parmi ces cas :
- les graphes n’ont pas le même nombre de sommets
- les graphes n’ont pas le même nombre d’arcs
- il existe un sommet de degré
dans le premier graphe mais pas dans le second (le degré d’un sommet, c’est le nombre d’arcs qui y sont connectés)
- le premier graphe a une structure, par exemple quatre sommets tous reliés les uns aux autres, qui n’existe pas dans le deuxième graphe
Il existe aussi un algorithme simple pour conclure à la question : numéroter tous les sommets du premier graphe, et essayer toutes les numérotations des sommets du deuxième graphe. Si on en trouve une qui marche, c’est gagné, et si on n’en trouve pas, c’est que les graphes ne sont pas isomorphes. Le problème de cet algorithme là, c’est qu’il réclame un temps d’exécution de 

Le problème est intéressant à – au moins – deux titres. Le premier, c’est qu’il arrive de résoudre des instances du problème dans la vraie vie, en chimie (identifier des composés dans une base de données) ou en électronique (vérifier qu’un circuit intégré est équivalent à son schéma). Comme on fait ça de manière quotidienne, c’est pas forcément le point critique. Le second titre, c’est que le problème « Graph Isomorphism » (GI, pour son petit nom) fait partie de cet ensemble de problèmes qu’on sait pas trop où mettre, d’un point de vue complexité. Il est dans NP – il suffit de fournir un étiquetage des sommets pour vérifier que deux graphes sont effectivement isomorphes – mais personne ne sait s’il est NP-complet (« aussi difficile que tous les autres problèmes de la classe NP »). Une hypothèse usuelle est que, si P est différent de NP, GI se trouve quelque part entre P et les problèmes NP-complets.
Jusqu’à l’an passé, la borne la plus basse qu’on avait pour la complexité de GI était 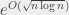




J’ai un peu pipoté quand je parlais des problèmes de la vraie vie. Parce qu’il faut également l’admettre, d’un point de vue pratique, suivant la tronche de la constante
J’aimerais être capable de dire « mais bon, j’ai lu la preuve et c’est très joli ». Parce que le papier, je l’ai ouvert, j’ai fait « AAAAAH », et je l’ai refermé. La vidéo de la conf de Babai, je l’ai regardée dans une espèce d’état second « alors c’est probablement très intéressant, mais je comprends quedalle ». Une version mise à jour du papier original (avec les corrections nécessaires) est apparemment en cours de rédaction ; j’ai comme vague projet d’essayer d’attaquer la compréhension de ce truc à un moment ou à un autre (avec assez peu d’optimisme sur le résultat final 😉 ).
