This blog post has been translated to English here: Intro to probability theory – part 1
Pouf pouf. Donc, j’ai trois personnes qui ont répondu à mon petit sondage et je les remercie. Yoogx m’a réclamé des algos aléatoires, donc je vais faire des algos aléatoires, mais avant je vais faire un peu de probas, histoire d’être sûre que tout le monde parle de la même chose. Évidemment, pour ledit Yoogx, ça va probablement pas être super utile ce que je raconte, mais espérons qu’il n’y aura pas que lui que la question des algos aléatoires intéresse, et sinon il est encore temps de s’exprimer 😉
Bon, donc, les probas. Les probas, c’est un peu pénible, parce que c’est des trucs qu’on utilise relativement souvent dans la vie… j’ai envie de dire « quotidienne », ça serait peut-être un peu exagéré, et en même temps ça arrive a être étonnamment contre-intuitif quand ça s’y met. Ça, ou alors l’être humain est nul en probas, ce qui est possible aussi.
J’ai pas super envie de définir formellement le concept de probabilité (« étant donné un univers 
Je suppose, pour éviter les petits malins, que je suis dans des conditions « correctes » : mon dé n’est pas pipé, ma pièce est une vraie pièce, etc.
On commence classique. Je lance une pièce, quelle est la probabilité qu’elle tombe sur le côté pile ? La réponse est 1/2 ; j’ai deux événements possibles (la pièce peut tomber côté pile ou côté face), et ils ont tous les deux la même probabilité de se produire. Idem si je lance un dé à six faces : la probabilité qu’il fasse un 4 est 1/6 ; j’ai six événements possibles qui ont tous la même probabilité de se produire. De manière générale, je vais me permettre de dire que si je fais une expérience (lancer un dé, lancer une pièce) qui a k résultats possibles, et que tous ces résultats possibles ont la même probabilité (« chance d’arriver »), alors la probabilité de chacun de ces résultats est 1/k.
Il se peut que tous les événements n’aient pas la même probabilité, mais il y a quelques règles immuables. Une probabilité est toujours comprise entre 0 et 1. Un événement qui n’arrive jamais a une probabilité 0 ; un événement qui arrive toujours a une probabilité 1. Si quelqu’un met dans mon porte-monnaie une pièce qui n’a que deux côté pile, si je la lance, elle tombe côté pile avec une probabilité 1 et côté face avec une probabilité 0. D’autre part, la somme de toutes les probabilités de tous les événements possibles de mon expérience est égale à 1. Dans le cas où j’ai k événements qui ont la même probabilité, ça fait effectivement k*1/k = 1. Si j’ai un dé qui a trois faces 1, 2 faces 2 et une face 3, la probabilité qu’il fasse 1 est 3/6 = 1/2, la probabilité qu’il fasse 2 est 2/6 = 1/3 et la probabilité qu’il fasse 3 est 1/6 ; la somme est 1/2 + 1/3 + 1/6 = 1.
Bon, maintenant, les trucs auxquels il faut faire un peu attention. Quelle est la probabilité que le dé (à six faces, normal) fasse 3 ou 5 ? Facile : la probabilité qu’il fasse 3, c’est 1/6, la probabilité qu’il fasse 5, c’est 1/6, 1/6+1/6 = 1/3. Ça, ça marche si les événements sont disjoints, c’est à dire si quand l’un est vrai, l’autre ne peut pas l’être : si j’ai fait un 5, alors je ne peux pas avoir fait un 3, et vice versa.
Ça ne marche pas si les événements peuvent se produire en même temps. Par exemple, je lance une pièce et un dé, et je m’intéresse à la probabilité que la pièce tombe sur pile, ou que le dé tombe sur 6. Je ne peux PAS dire que c’est égal à la probabilité que la pièce tombe sur pile (1/2), plus la probabilité que le dé tombe sur 6 (1/6), pour un total de 2/3. Une manière de voir ça, c’est de modifier un peu l’expérience pour voir que ça ne marche pas à tous les coups. Par exemple, la probabilité que le dé fasse 1, 2, 3 ou 4 est de 4/6 = 2/3. La probabilité que la pièce fasse pile est de 1/2. Ce n’est pas possible que la probabilité que l’un ou l’autre arrive fasse la somme de ces deux probabilités = 2/3 + 1/2 = 7/6… ce qui est supérieur à 1 ! (Et une probabilité est toujours inférieure ou égale à 1).
Un truc qui est toujours vrai, par contre, c’est que si j’ai deux événements A et B, alors
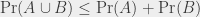
c’est à dire que la probabilité de l’union de deux événements (événement A ou événement B) est toujours inférieure à la somme de la probabilité des deux événements. On peut étendre ça à plusieurs événements : la probabilité de l’union de plusieurs événements est inférieure à la somme de la probabilité de tous les événements. Ça peut paraître tout con et pas très intéressant, mais en pratique c’est très utilisé. En anglais, ça s’appelle l’union bound (la « borne de l’union » ?), en français l’inégalité de Boole. Cette inégalité n’est pas toujours très utile. Dans le cas « mon dé fait 1, 2, 3 ou 4, ou ma pièce fait pile », elle borne la probabilité à 7/6… ce qu’on savait déjà, puisque 7/6 est plus grand que 1. Elle est déjà un peu plus utile pour borner la probabilité que le dé fasse 6 ou que la pièce tombe sur pile, on sait que cette probabilité est inférieure à 2/3. En pratique, dans le contexte des algorithmes aléatoires, elle est très utilisée : les probabilités qu’on considère sont toutes petites, et on peut en ajouter beaucoup avant que la borne n’ait plus de sens. Elle n’est pas toujours suffisante non plus, mais c’est un outil à garder précieusement.
Dans le cas qui nous intéresse ici, cependant, l’outil le plus utile c’est le principe d’inclusion-exclusion. Pour deux événements A et B, il s’énonce comme ça :

c’est-à-dire que la probabilité que l’événement A ou l’événement B arrive est égal à la somme des probabilités des deux événements, moins la probabilité que les deux événements arrivent en même temps. L’idée, c’est que si les deux événements peuvent arriver en même temps, on compte cette probabilité là « deux fois » si on fait la somme. Ça se voit sans doute mieux avec des patates (diagramme de Venn, on dit, quand on est distingué) :

Si je considère tout ce qui est contenu dans le hachuré vert, et tout ce qui est contenu dans le hachuré rose, je compte deux fois ce qui est hachuré vert et hachuré rose, donc je retire une fois ce qui est hachuré vert et hachuré rose pour retomber sur mes pattes.
Bon, évidemment, ça pose la question de savoir comment calculer la probabilité que deux événements arrivent. Il y a le cas facile, et le cas compliqué. Dans le cas facile, les événements sont dits indépendants : la probabilité de l’un n’a aucune influence sur la probabilité de l’autre. C’est une notion qui est à peu près claire (bien que pas forcément intuitive) si on considère des dés et des pièces, mais c’est une notion à laquelle il faut généralement faire super attention quand on veut l’appliquer. Prouver que deux événements sont indépendants peut s’avérer compliqué, et s’en sortir quand ils ne le sont pas… aussi.
Quand deux événements sont indépendants, on a

c’est-à-dire que la probabilité que les deux événements arrivent est égale au produit de la probabilité des deux événements. Si je lance une pièce et un dé, le fait que la pièce tombe sur pile et le fait que le dé fasse 6 sont indépendants : l’un n’a aucune influence sur l’autre. La probabilité que les deux arrivent est donc 1/2 × 1/6 = 1/12. Remarquons que cette probabilité conjointe est plus petite que 1/2 et plus petite que 1/6. C’est « évident » au sens où une probabilité est inférieure à 1, et donc quand on multiplie deux probabilités entre elles le résultat est inférieur aux deux. Une autre manière de voir ça c’est que le fait que les deux événements indépendants se produisent, ben c’est moins probable que le fait que seulement l’un des deux se produise.
Pour des exemples d’événements qui ne sont pas indépendants, on peut par exemple considérer l’événement A « le dé fait 1 » et l’événement B « le dé fait un nombre impair ». Dans ce cas là, les deux événements ne sont pas indépendants, puisque si le dé fait 1, alors le dé fait un nombre impair ; et si le dé fait 2, alors il ne peut pas faire un nombre impair en même temps. Dans ce cas précis, l’événement A est inclus dans l’événement B, donc c’est facile : l’intersection des deux événements, c’est l’événement le plus petit : l’événement 
Bon, et maintenant, une dernière pour la route : il me reste à parler de probabilités conditionnelles. Les probabilités conditionnelles, c’est justement une manière de gérer les dépendances entre des événements. On note les probabilités conditionnelles Pr(A | B), et on lit ça « probabilité de A sachant B », et on comprend ça comme « probabilité de A sachant que B arrive/est arrivé ». Si A et B sont indépendants, alors Pr(A | B) = Pr(A) – savoir que B se passe n’a aucune influence sur la probabilité de A. Pour le cas précédent, où A est l’événement « le dé fait 1 » et B est l’événement « le dé fait un nombre impair », on peut voir le « sachant B » comme une restriction de l’ensemble des événements possibles. Le dé a fait un nombre impair, on le sait ; avec la même probabilité il a donc fait 1, 3 ou 5, mais la probabilité, sachant qu’il ait fait un nombre impair, qu’il ait fait 2, 4 ou 6 est 0. Donc on a Pr(A | B) = 1/3.
Il y a une formule « générale » pour les probabilités conditionnelles :
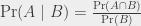
On peut re-dériver, à partir de cette formule, le fait que si A et B sont indépendants, alors Pr(A | B) = Pr(A), parce qu’alors
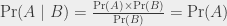
Elle est aussi très utilisée dans l’autre sens :

parce qu’il arrive qu’il soit plus facile de comprendre ce qu’il se passe dans le contexte des probabilités conditionnelles que dans le contexte de deux événements qui arrivent en même temps de façon non indépendante. Et il faudrait techniquement que je parle de la loi des probabilités totales ici, mais je crois que ça va allonger un peu trop un billet qui est déjà pas court, donc je ferai ça plus tard.
Dans le billet prochain, on parlera de variables aléatoires, parce que c’est pareil, ça va pas rentrer dans un billet de taille raisonnable d’en parler ici 🙂
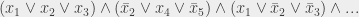

 et
et  , je ne crée pas d’arc entre eux. Pour ma mini-formule au-dessus, voilà ce que donne le graphe en question :
, je ne crée pas d’arc entre eux. Pour ma mini-formule au-dessus, voilà ce que donne le graphe en question :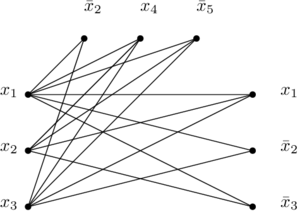
 et
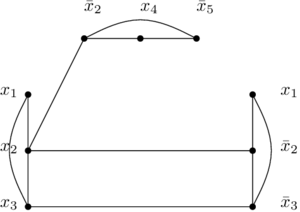
et  , qu’on n’a choisi que des littéraux qui ont la valeur 1, et qu’on ne peut pas avoir en même temps
, qu’on n’a choisi que des littéraux qui ont la valeur 1, et qu’on ne peut pas avoir en même temps  et
et 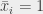 . Donc, toutes les paires dans les m sommets sont connectées entre elles, donc on a une clique de taille m, ce qu’on voulait démontrer.
. Donc, toutes les paires dans les m sommets sont connectées entre elles, donc on a une clique de taille m, ce qu’on voulait démontrer. et
et  opérations, et que dans tous les cas c’est pas polynomial. Et, de manière générale, personne ne sait si c’est possible de faire ça en temps polynomial, puisque CLIQUE est NP-complet et qu’on ne sait pas si P est égal à NP. Beaucoup de gens supposent que non, mais personne ne sait.
opérations, et que dans tous les cas c’est pas polynomial. Et, de manière générale, personne ne sait si c’est possible de faire ça en temps polynomial, puisque CLIQUE est NP-complet et qu’on ne sait pas si P est égal à NP. Beaucoup de gens supposent que non, mais personne ne sait.