This blog post has been translated to English here: Intro to probability theory – part 1
Pouf pouf. Donc, j’ai trois personnes qui ont répondu à mon petit sondage et je les remercie. Yoogx m’a réclamé des algos aléatoires, donc je vais faire des algos aléatoires, mais avant je vais faire un peu de probas, histoire d’être sûre que tout le monde parle de la même chose. Évidemment, pour ledit Yoogx, ça va probablement pas être super utile ce que je raconte, mais espérons qu’il n’y aura pas que lui que la question des algos aléatoires intéresse, et sinon il est encore temps de s’exprimer 😉
Bon, donc, les probas. Les probas, c’est un peu pénible, parce que c’est des trucs qu’on utilise relativement souvent dans la vie… j’ai envie de dire « quotidienne », ça serait peut-être un peu exagéré, et en même temps ça arrive a être étonnamment contre-intuitif quand ça s’y met. Ça, ou alors l’être humain est nul en probas, ce qui est possible aussi.
J’ai pas super envie de définir formellement le concept de probabilité (« étant donné un univers 
Je suppose, pour éviter les petits malins, que je suis dans des conditions « correctes » : mon dé n’est pas pipé, ma pièce est une vraie pièce, etc.
On commence classique. Je lance une pièce, quelle est la probabilité qu’elle tombe sur le côté pile ? La réponse est 1/2 ; j’ai deux événements possibles (la pièce peut tomber côté pile ou côté face), et ils ont tous les deux la même probabilité de se produire. Idem si je lance un dé à six faces : la probabilité qu’il fasse un 4 est 1/6 ; j’ai six événements possibles qui ont tous la même probabilité de se produire. De manière générale, je vais me permettre de dire que si je fais une expérience (lancer un dé, lancer une pièce) qui a k résultats possibles, et que tous ces résultats possibles ont la même probabilité (« chance d’arriver »), alors la probabilité de chacun de ces résultats est 1/k.
Il se peut que tous les événements n’aient pas la même probabilité, mais il y a quelques règles immuables. Une probabilité est toujours comprise entre 0 et 1. Un événement qui n’arrive jamais a une probabilité 0 ; un événement qui arrive toujours a une probabilité 1. Si quelqu’un met dans mon porte-monnaie une pièce qui n’a que deux côté pile, si je la lance, elle tombe côté pile avec une probabilité 1 et côté face avec une probabilité 0. D’autre part, la somme de toutes les probabilités de tous les événements possibles de mon expérience est égale à 1. Dans le cas où j’ai k événements qui ont la même probabilité, ça fait effectivement k*1/k = 1. Si j’ai un dé qui a trois faces 1, 2 faces 2 et une face 3, la probabilité qu’il fasse 1 est 3/6 = 1/2, la probabilité qu’il fasse 2 est 2/6 = 1/3 et la probabilité qu’il fasse 3 est 1/6 ; la somme est 1/2 + 1/3 + 1/6 = 1.
Bon, maintenant, les trucs auxquels il faut faire un peu attention. Quelle est la probabilité que le dé (à six faces, normal) fasse 3 ou 5 ? Facile : la probabilité qu’il fasse 3, c’est 1/6, la probabilité qu’il fasse 5, c’est 1/6, 1/6+1/6 = 1/3. Ça, ça marche si les événements sont disjoints, c’est à dire si quand l’un est vrai, l’autre ne peut pas l’être : si j’ai fait un 5, alors je ne peux pas avoir fait un 3, et vice versa.
Ça ne marche pas si les événements peuvent se produire en même temps. Par exemple, je lance une pièce et un dé, et je m’intéresse à la probabilité que la pièce tombe sur pile, ou que le dé tombe sur 6. Je ne peux PAS dire que c’est égal à la probabilité que la pièce tombe sur pile (1/2), plus la probabilité que le dé tombe sur 6 (1/6), pour un total de 2/3. Une manière de voir ça, c’est de modifier un peu l’expérience pour voir que ça ne marche pas à tous les coups. Par exemple, la probabilité que le dé fasse 1, 2, 3 ou 4 est de 4/6 = 2/3. La probabilité que la pièce fasse pile est de 1/2. Ce n’est pas possible que la probabilité que l’un ou l’autre arrive fasse la somme de ces deux probabilités = 2/3 + 1/2 = 7/6… ce qui est supérieur à 1 ! (Et une probabilité est toujours inférieure ou égale à 1).
Un truc qui est toujours vrai, par contre, c’est que si j’ai deux événements A et B, alors
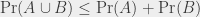
c’est à dire que la probabilité de l’union de deux événements (événement A ou événement B) est toujours inférieure à la somme de la probabilité des deux événements. On peut étendre ça à plusieurs événements : la probabilité de l’union de plusieurs événements est inférieure à la somme de la probabilité de tous les événements. Ça peut paraître tout con et pas très intéressant, mais en pratique c’est très utilisé. En anglais, ça s’appelle l’union bound (la « borne de l’union » ?), en français l’inégalité de Boole. Cette inégalité n’est pas toujours très utile. Dans le cas « mon dé fait 1, 2, 3 ou 4, ou ma pièce fait pile », elle borne la probabilité à 7/6… ce qu’on savait déjà, puisque 7/6 est plus grand que 1. Elle est déjà un peu plus utile pour borner la probabilité que le dé fasse 6 ou que la pièce tombe sur pile, on sait que cette probabilité est inférieure à 2/3. En pratique, dans le contexte des algorithmes aléatoires, elle est très utilisée : les probabilités qu’on considère sont toutes petites, et on peut en ajouter beaucoup avant que la borne n’ait plus de sens. Elle n’est pas toujours suffisante non plus, mais c’est un outil à garder précieusement.
Dans le cas qui nous intéresse ici, cependant, l’outil le plus utile c’est le principe d’inclusion-exclusion. Pour deux événements A et B, il s’énonce comme ça :

c’est-à-dire que la probabilité que l’événement A ou l’événement B arrive est égal à la somme des probabilités des deux événements, moins la probabilité que les deux événements arrivent en même temps. L’idée, c’est que si les deux événements peuvent arriver en même temps, on compte cette probabilité là « deux fois » si on fait la somme. Ça se voit sans doute mieux avec des patates (diagramme de Venn, on dit, quand on est distingué) :

Si je considère tout ce qui est contenu dans le hachuré vert, et tout ce qui est contenu dans le hachuré rose, je compte deux fois ce qui est hachuré vert et hachuré rose, donc je retire une fois ce qui est hachuré vert et hachuré rose pour retomber sur mes pattes.
Bon, évidemment, ça pose la question de savoir comment calculer la probabilité que deux événements arrivent. Il y a le cas facile, et le cas compliqué. Dans le cas facile, les événements sont dits indépendants : la probabilité de l’un n’a aucune influence sur la probabilité de l’autre. C’est une notion qui est à peu près claire (bien que pas forcément intuitive) si on considère des dés et des pièces, mais c’est une notion à laquelle il faut généralement faire super attention quand on veut l’appliquer. Prouver que deux événements sont indépendants peut s’avérer compliqué, et s’en sortir quand ils ne le sont pas… aussi.
Quand deux événements sont indépendants, on a

c’est-à-dire que la probabilité que les deux événements arrivent est égale au produit de la probabilité des deux événements. Si je lance une pièce et un dé, le fait que la pièce tombe sur pile et le fait que le dé fasse 6 sont indépendants : l’un n’a aucune influence sur l’autre. La probabilité que les deux arrivent est donc 1/2 × 1/6 = 1/12. Remarquons que cette probabilité conjointe est plus petite que 1/2 et plus petite que 1/6. C’est « évident » au sens où une probabilité est inférieure à 1, et donc quand on multiplie deux probabilités entre elles le résultat est inférieur aux deux. Une autre manière de voir ça c’est que le fait que les deux événements indépendants se produisent, ben c’est moins probable que le fait que seulement l’un des deux se produise.
Pour des exemples d’événements qui ne sont pas indépendants, on peut par exemple considérer l’événement A « le dé fait 1 » et l’événement B « le dé fait un nombre impair ». Dans ce cas là, les deux événements ne sont pas indépendants, puisque si le dé fait 1, alors le dé fait un nombre impair ; et si le dé fait 2, alors il ne peut pas faire un nombre impair en même temps. Dans ce cas précis, l’événement A est inclus dans l’événement B, donc c’est facile : l’intersection des deux événements, c’est l’événement le plus petit : l’événement 
Bon, et maintenant, une dernière pour la route : il me reste à parler de probabilités conditionnelles. Les probabilités conditionnelles, c’est justement une manière de gérer les dépendances entre des événements. On note les probabilités conditionnelles Pr(A | B), et on lit ça « probabilité de A sachant B », et on comprend ça comme « probabilité de A sachant que B arrive/est arrivé ». Si A et B sont indépendants, alors Pr(A | B) = Pr(A) – savoir que B se passe n’a aucune influence sur la probabilité de A. Pour le cas précédent, où A est l’événement « le dé fait 1 » et B est l’événement « le dé fait un nombre impair », on peut voir le « sachant B » comme une restriction de l’ensemble des événements possibles. Le dé a fait un nombre impair, on le sait ; avec la même probabilité il a donc fait 1, 3 ou 5, mais la probabilité, sachant qu’il ait fait un nombre impair, qu’il ait fait 2, 4 ou 6 est 0. Donc on a Pr(A | B) = 1/3.
Il y a une formule « générale » pour les probabilités conditionnelles :
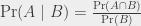
On peut re-dériver, à partir de cette formule, le fait que si A et B sont indépendants, alors Pr(A | B) = Pr(A), parce qu’alors
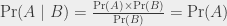
Elle est aussi très utilisée dans l’autre sens :

parce qu’il arrive qu’il soit plus facile de comprendre ce qu’il se passe dans le contexte des probabilités conditionnelles que dans le contexte de deux événements qui arrivent en même temps de façon non indépendante. Et il faudrait techniquement que je parle de la loi des probabilités totales ici, mais je crois que ça va allonger un peu trop un billet qui est déjà pas court, donc je ferai ça plus tard.
Dans le billet prochain, on parlera de variables aléatoires, parce que c’est pareil, ça va pas rentrer dans un billet de taille raisonnable d’en parler ici 🙂

Salut, j’ai bien aimé l’article, même s’il ne m’apprend pas grand chose. J’aurais juste deux typos à relever :
– Tu t’es trompé en énonçant la formule Pr(A ∩ B) = Pr(A) × Pr(B) pour les évènements indépendants. (L’intersection est devenue union dans l’article)
– De même, « La probabilité que A et B soient valides correspond exactement à la probabilité que le dé fasse 1 (parce que c’est le seul cas qui soit à la fois dans l’ensemble {1, 6} et impair) » : ne voulais-tu pas plutôt dire « l’ensemble {1,4,6} ?
Bonne journée.
Bien vu, merci, je corrige.
NON MAIS EN FAIT C’ÉTAIT JUSTE POUR VOIR SI VOUS SUIVIEZ (kof).
Bonjour,
Pour moi, il manque une chose fondamentale : la définition d’une probabilité « Le rapport entre le nombre de cas favorables et le nombre de cas possibles », ce qui implique nécessairement que une probabilité est comprise entre 0 et 1. Cette définition est quelque-fois contestée pour les variables continues. Heureusement, on a inventé, il y a bien longtemps, les nombres réels.
On peut lire dans la page de Wikipédia « Théorie des probabilités » que ces axiomes ont permis d’expliquer le Paradoxe de la corde de Bertrand. J’aimerais avoir votre avis sur ce point.
Cordialement.
Oui, j’ai évité la définition formelle à dessein – bon, pour autant que je me souvienne de ce que j’avais dans la tête il y a quatre ans 😀
Le coup des axiomes tels que donnés par la Wikipedia – en bref, qu’on a un ensemble de tous les cas possibles, qu’on a une tribu d’événements pour lesquels on peut calculer la probabilité de réalisation, et que la mesure de probabilité est positive, additive et a une masse unitaire – permet de définir les choses de manière formelle et abstraite et, essentiellement, de faire des maths dessus 😛 En pratique une fois les choses définies on s’intéresse à la mesure de probabilité P, avec P(A) la probabilité de l’événement A. Et le paradoxe de la corde de Bertrand se résout par le fait que la fonction P n’est pas la même pour tous les « choix d’une corde au hasard » – et ne donne donc pas les mêmes résultats. Y’a des choses rigolotes en fin de http://numerisation.irem.univ-mrs.fr/WR/IWR97083/IWR97083.pdf qui donne plusieurs fonctions possibles pour plusieurs modèles.
Heu, voilà, je sais pas trop quel « avis » je peux avoir, mais c’est ce qui me vient à l’idée là tout de suite 😛
Bonjour,
Merci pour votre réponse et le texte fort intéressant de l’IREM de Besançon. Je n’ai pas lu en détail le paragraphe sur Monty-Hall. En fait, la question à se poser : « Le candidat sait-il que le présentateur ne va pas ouvrir la porte cachant la voiture ? ». Si oui, alors il va choisir une porte quelconque, et changera son choix, puisqu’il a forcément un chance sur 2 d’avoir la voiture, sinon, il n’a aucune raison de changer ce choix initial.
La fin de l’article V page 14 commence par « Les lois de probabilités ne sont pas inscrites dans la nature … ».
Eh bien si, justement. Si on réalise la même expérience avec les mêmes méthodes, on obtiendra toujours des résultats qui répondent aux dites lois de probabilités, qui sont assez simples, le postulat de la moyenne, la loi des grands nombres et la loi normale, représentée par la courbe de Gauss, et bien connue via le TCL.
Il ne peut pas y avoir de paradoxe (type Bertrand) en math. Si c’était le cas; l’affirmation « les math constituent une science exacte et fiable » serait fausse, contre-exemple incontestable : la solution de la corde de Bertrand dépend de l’humeur ou du choix du mathématicien qui modélise le calcul sur son papier, alors que dans le monde réel, on peut faire l’expérience aussi souvent que l’on veut, par la méthode et les expérimentateurs que l’on veut, on obtiendra toujours le même résultat.
Concernant ce « paradoxe », Jacques Harthong a fait une démonstration parfaitement précise et rigoureuse dans son livre « Probabilités et statistiques », j’ai trouvé d’autres démonstrations, mais l’impact médiatique de ces certitudes fausse tout raisonnement rigoureux.
Pour conclure, je me demande comment les statisticiens défendent leur spécialité si ces lois ne sont pas inscrites dans la nature et que « ça dépend de l’humeur du matheux ».
Sauf que, pour le paradoxe de Bertrand, ça dépend immédiatement non pas de la modélisation, mais de la manière de choisir une corde au hasard. On peut faire l’expérience aussi souvent que l’on veut, certes, mais _quelle_ expérience est exactement la question que l’on se pose. « Prendre une corde au hasard sur le cercle » ne veut rien dire si on ne définit pas la manière de prendre une corde au hasard, qui définit lui-même la distribution de probabilité (et par conséquent la probabilité qu’une corde soit plus grande qu’un côté d’un triangle équilatéral inscrit).
Bref, les statisticiens (et les gens qui font des probabilités) n’ont pas vraiment de souci à se faire 😉
Bonjour,
Concernant la code de Bertrand, je n’ai rien d’autre à dire. Par contre, j’ai lu dernièrement une question posée, il s’agissait du comptage d’un grand nombre de réponses. La question posée était à propos de la moyenne ou la médiane ? puis pour la moyenne, s’agit-il de la moyenne arithmétique, harmonique, géométrique, ou une autre. Là, les réponses sont vraiment évasives. Les statisticiens n’ont assurément pas de souci à se faire : ils appliquent méthodes et formules. Par contre, ceux qui utilisent les probabilités et les statistiques, eux ne savent pas ce qui se rattache à quoi, où sont les justifications, les conclusions sont-elle bonnes, que faire quand on leur répond « fais comme tu veux » ou « ça dépend » ou « pour la corde, elle sait bien où se trouve l’une de ses extrémités » etc.
Bah, c’est comme dans à peu près tous les domaines – on peut faire les choses rigoureusement, ou on peut faire n’importe quoi 😛
Juste une petite réponse, pour savoir ce dont on parle, il faudrait définir les termes probabilité et hasard. Sinon, il est compréhensible de dire que la corde sait où se trouve son origine, sa direction, ou son centre, ou tout ce qu’on voudra. Il ne faudra pas oublier de quel hasard parle Bertrand, comme chacun sait, il y a plusieurs hasards, disons autant que de probabilistes.
Les probabilistes ont l’habitude de dire « c’est comme on veut » ou « ça dépend ». Ca on le sait, pas le peine de le rappeler.