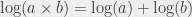Bon, ça y est, j’ai fini les deux billets qui savaient à peu près où ils allaient (un billet général sur l’informatique théorique, et un billet pour expliquer ce qu’est un logarithme parce que c’est toujours utile). Et après on a fait une petite pause, parce que bon. Donc maintenant je vais rentrer dans les choses un peu plus compliquées, et qui me sont plus difficiles à expliquer aussi. Donc j’écris, et puis on verra bien ce que ça donne à la fin. Ajoutons à cela que je veux essayer d’expliquer les choses en évitant au maximum le formalisme mathématique qui m’est maintenant « naturel » (mais croyez-moi, il a fallu me le rentrer dans le crâne à coups de marteau) : je sais vraiment pas ce que ça va donner. J’ai aussi décidé de couper ce billet en deux, parce qu’il est déjà fort long comme ça. Je pense que le deuxième sera plus court.
J’ai déjà défini un algorithme comme étant une suite bien définie d’opérations qui permettent d’arriver à un résultat. Je ne vais pas aller beaucoup plus loin dans la définition formelle, parce que je pense que ce n’est pas utile - du moins pas pour le moment. Et je vais définir, également de façon très peu formelle, la complexité algorithmique comme la quantité de ressources qu’il me faut pour exécuter mon algorithme. Par ressources, j’entendrai le plus souvent « le temps », c’est-à-dire le temps qu’il me faut pour exécuter un algorithme, parfois « l’espace », c’est à dire la quantité de mémoire (pensez-y comme à de la mémoire vive ou du disque dur) qu’il me faut pour exécuter mon algorithme.
Je vais prendre un exemple très classique pour illustrer mon propos, qui est celui du tri. Et pour donner un exemple concret de cet exemple classique, supposons que j’aie une bibliothèque pleine de livres. (Une supposition absolument et complètement folle.) Et qu’il me vienne l’idée sotte et complètement grenue de vouloir les trier, disons par ordre alphabétique de nom d’auteur (et de titre à nom d’auteur égal). Je dis qu’un livre A est « plus petit » qu’un autre livre B s’il doit être rangé avant dans la bibliothèque, et qu’il est « plus grand » s’il doit être rangé après. Avec cette définition, les bouquins d’Asimov sont plus petits que les bouquins de Clarke qui sont plus petits que les bouquins de Pratchett. Je vais garder cet exemple pendant tout le billet et je vais faire le parallèle avec les notions algorithmiques correspondantes.
Je commence donc par définir ce dont je parle. L’algorithme que j’étudie, c’est l’algorithme de tri ; c’est celui qui me permet de passer d’une bibliothèque en bordel à une bibliothèque rangée dans l’ordre alphabétique. En « entrée » de mon algorithme, c’est-à-dire les données que je donne à traiter à mon algorithme, j’ai une bibliothèque en bordel. En « sortie » de mon algorithme, j’ai les données traitées par mon algorithme, c’est-à-dire une bibliothèque rangée.
La première chose qu’on peut remarquer, c’est que plus on a de livres, plus c’est long à trier. Ça vient de deux choses. La première, c’est que si on considère une opération « élémentaire » du tri (par exemple, mettre le livre dans la bibliothèque), c’est plus long de faire ça 100 fois que 10 fois. La deuxième, c’est que si on considère tout ce qu’on fait pour chaque livre, plus il y a de livres, plus c’est long à faire. C’est plus long de chercher quel est le bon emplacement pour un livre parmi 100 que parmi 10.
Et voilà ce à quoi on s’intéresse ici : la manière dont le temps nécessaire à obtenir une bibliothèque rangée évolue en fonction du nombre de livres ou, de façon plus générale, la manière dont le temps nécessaire à obtenir une séquence triée d’éléments dépend du nombre d’éléments à trier.
Ce temps dépend de la méthode de tri qu’on utilise. Par exemple, on peut choisir une méthode de tri très très longue : tant que la bibliothèque n’est pas triée, on remet tout par terre et on met les livres dans un ordre aléatoire dans la bibliothèque. Pas trié ? On recommence. Ça, typiquement, ça va être très long. À l’autre bout du spectre, on a Mary Poppins : un Supercalifragilistic, et paf, la bibliothèque est rangée. La méthode Mary Poppins a d’ailleurs une particularité : elle ne dépend pas du nombre de livres à ranger. On dit que Mary Poppins s’exécute en « temps constant » : quel que soit le nombre de livres à ranger, ils seront rangés dans la seconde. En pratique, il y a bien une raison pour laquelle la méthode Mary Poppins fait rêver, c’est bien que c’est magique et difficilement réalisable en réalité.
Revenons, donc, à la réalité, et aux algorithmes de tri autres que Mary Poppins. Pour analyser la manière dont mon tri marche, je considère trois opérations élémentaires dont je peux avoir besoin pendant que je range :
- comparer deux livres pour savoir si l’un se range avant ou après l’autre
- mettre le livre dans la bibliothèque
- et, en supposant que mes livres en bordel soient en bordel sur une table, le déplacement d’un livre sur la table.
Et je vais supposer aussi que ces trois opérations prennent le même temps, disons une seconde. Ça ne serait pas très efficace pour un ordinateur, mais je pense que c’est plutôt efficace pour un humain, et ça donne une idée. Je vais aussi supposer que ma bibliothèque est un peu magique, c’est-à-dire que ses rayonnages s’adaptent tous seuls et que les livres s’y placent sans avoir de problème de « rha, j’ai plus de place sur cette étagère, il faut que je descende des bouquins sur celle d’en-dessous, qui est pleine aussi, et là c’est le drame ». Pareil, ma table est magique, et déplacer un livre où je veux ne pose pas de problème. En pratique, il faudrait se poser ce genre de questions, y compris d’un point de vue algorithmique (quelle est la pénalité d’avoir à faire ça, est-ce que je peux l’éviter en étant malin). Mais comme je ne suis pas en train d’écrire un billet sur les tris mais sur la complexité algorithmique, je simplifie. (Et pour ceux qui savent de quoi je parle, oui, je sais que mon modèle est discutable. C’est un modèle, c’est mon modèle, je fais ce que je veux avec, et les explications restent valides dans mon modèle même s’il est discutable).
Un premier tri
Voici maintenant une première manière de trier. Je suppose que j’ai vidé ma bibliothèque en bordel sur ma table, et que je veux ranger les bouquins un par un. Le scénario suivant est assez peu réaliste pour un humain qui, probablement, se souviendrait approximativement de l’endroit où mettre le livre, mais essayez d’imaginer la situation suivante.
- Je prends mon premier bouquin, je le mets dans la bibliothèque.
- Je prends un deuxième bouquin, je compare avec le premier : s’il doit être rangé avant, je le mets devant, s’il doit être rangé après, je le mets après.
- Je prends le troisième bouquin, je compare avec le premier. S’il doit être rangé avant, je le mets en première position. S’il doit être rangé après, je compare avec le deuxième bouquin que j’ai rangé. S’il doit être rangé avant, je le mets entre le bouquin 1 et le bouquin 2. S’il doit être rangé après, je le mets en dernière position.
- Et ainsi de suite, jusqu’à ce que ma bibliothèque soit rangée. À chaque livre que j’insère, je compare, dans l’ordre, avec les livres déjà en place, et je l’insère entre le dernier livre qui est « plus petit » et le dernier livre qui est « plus grand ».
Et maintenant, je me demande combien de temps ça prend si j’ai, mettons, 100 livres, ou un nombre quelconque de livres. Je vais donner la réponse dans les deux cas : pour 100 livres et pour un nombre n de livres. Le temps pour n livres sera une fonction du nombre de livres, et c’est ce qui m’intéresse vraiment ici, ou plutôt ce qui m’intéressera vraiment dans le deuxième billet de cette introduction.
La réponse est que ça dépend de l’ordre dans lequel mes livres étaient au début quand ils étaient sur ma table. Il peut arriver, pourquoi pas, qu’ils étaient déjà triés. J’aurais peut-être dû vérifier ça avant de tout poser sur la table, ça aurait été plus malin, mais je n’y ai pas pensé avant. Il se trouve que c’est la pire chose qui puisse m’arriver avec cet algorithme, parce qu’à chaque fois que je veux ranger un livre, comme il est plus grand que tous ceux que j’ai rangés avant, il faut que je compare avec tous les livres que j’ai rangés avant. Comptons :
- Je mets le premier livre dans la bibliothèque. Nombre d’opérations : 1.
- Je compare le deuxième livre avec le premier livre. Je le mets dans la bibliothèque. Nombre d’opérations : 2.
- Je compare le troisième livre avec le premier livre. Je compare le troisième livre avec le deuxième livre. Je le mets dans la bibliothèque. Nombre d’opérations : 3.
- Je compare le quatrième livre avec le premier livre. Je compare le quatrième livre avec le deuxième livre. Je compare le quatrième livre avec le troisième livre. Je le mets dans la bibliothèque. Nombre d’opérations : 4.
- Et ainsi de suite. À chaque fois que j’insère un livre, je le compare avec tous les livres qui l’ont précédé ; quand j’insère le 50e livre je fais donc 49 comparaisons, plus l’ajout du livre dans la bibliothèque, 50 opérations.
Donc pour insérer mes 100 livres, s’ils sont dans l’ordre au début, il me faut 1+2+3+4+5+…+99+100 opérations. Il se trouve, et je vais vous demander de me croire sur parole ici (c’est facile à démontrer, mais c’est pas l’objet) que 1+2+3+4+5+…+99+100, ça fait exactement (100*101)/2 = 5050 opérations. Et que, si je n’ai plus 100 livres, mais n livres qui se trouvent être dans l’ordre, il me faut n*(n+1)/2 = (n² + n)/2 opérations.
Supposons maintenant que mes livres étaient exactement dans l’ordre inverse duquel ils doivent être rangés. Ben cette fois ci, c’est la meilleure chose qui puisse m’arriver avec cet algorithme, parce que le livre que j’ajoute est toujours plus petit que tous ceux que j’ai rangés avant, donc il suffit de comparer avec le premier livre.
- Je mets le premier livre dans la bibliothèque. Nombre d’opérations : 1.
- Je compare le deuxième livre avec le premier livre. Je le mets dans la bibliothèque. Nombre d’opérations : 2.
- Je compare le troisième livre avec le premier livre. Je le mets dans la bibliothèque. Nombre d’opérations : 2.
- Et ainsi de suite : je compare toujours avec le premier livre, il est toujours plus petit, et j’ai toujours 2 opérations.
Donc si mes 100 livres sont exactement dans l’ordre inverse, je fais 1+2+2+2+…+2 = 1 + 99*2 opérations = 199 opérations. Et, si j’ai n livres dans l’ordre inverse, il me faut 1+2*(n-1) = 2n – 1 opérations.
C’est à partir d’ici que ça se corse un peu, parce que la situation devient moins bien définie, et que je vais commencer à faire des approximations dans tous les sens. J’essaie de justifier à chaque fois les approximations que je fais et pourquoi elles sont valides ; il est possible, cependant, que je zappe quelques étapes. N’hésitez pas à râler dans les commentaires si je suis complètement partie en sucette, parce que j’ai un peu de mal à me rendre compte 
Je vais maintenant supposer que mes livres en bordel sont dans un état qui fait que, à chaque fois que j’ajoute un livre, il est inséré à peu près au milieu de ce qui a déjà été trié. (Je dis à peu près parce que si j’ai trié 5 livres, je vais typiquement ranger le 6e après le 2e ou après le 3e livre – les emplacements sont entiers, je vais pas le ranger après le 2.5e livre). Supposons que j’insère le livre numéro i ; j’estime le nombre de comparaisons que je fais à i/2 + 1, qui est supérieur ou égal au nombre de comparaisons que je fais effectivement. Pour voir ça, je distingue sur le fait que i soit pair ou impair. On peut montrer que ça marche pour tous les nombres ; je vais juste donner deux exemples pour expliquer qu’effectivement ça a de bonnes chances de marcher.
Si j’insère le 6e livre, j’ai 5 livres déjà rangés ; supposons que je veuille le ranger après le 3e livre (au « presque milieu »), je fais 4 comparaisons (parce qu’il est plus grand que le premier, deuxième, troisième livre, mais plus petit que le 4e) ; on a i/2 + 1 = 6/2+1 = 4.
Si j’insère le 7e livre, j’ai 6 livres déjà rangés, je veux le ranger après le 3e livre aussi (exactement au milieu), je fais également 4 comparaisons, et j’ai i/2+1 = 7/2 + 1 = 4.5.
Donc, je vais estimer le nombre d’opérations qu’il me faut pour ranger 100 livres, en comptant « large », et en me permettant des « demis-opérations ». Le but du jeu n’est pas ici de dénombrer exactement, mais d’avoir un ordre de grandeur, qui se trouvera être supérieur au nombre exact d’opérations.
- Livre 1 : 1/2+1 = 1.5, plus le rangement, 2.5 opérations (je n’ai pas besoin de comparer, en fait, ici ; je le fais quand même parce que ça me facilite les calculs à la fin)
- Livre 2 : 2/2 + 1 = 2, plus le rangement, 3 opérations (pareil ici, j’ai une comparaison de trop, parce que je n’ai qu’un seul bouquin de rangé, mais encore une fois je ne suis pas à un près).
- Livre 3 : 3/2 + 1 = 2.5, plus le rangement, 3.5 opérations
- Livre 4 : 4/2 + 1 = 3, plus le rangement, 4 opérations
Si je continue comme ça et que je range un peu mes calculs, j’ai, pour 100 livres, au plus
(1+2+3+4+…+99+100)/2 + 100 + 100 = (100*101/2)/4 + 200 = 2725 opérations.
Le premier élément de ma somme vient du « i/2 » que j’ai dans tous mes calculs de nombre de comparaisons. Le premier 100 vient du « 1 » que j’ajoute chaque fois que je compte les comparaisons (et je fais ça 100 fois), le deuxième 100 vient du « 1 » que j’ajoute à chaque fois que je compte le rangement des livres, et que je fais également 100 fois.
Ce 2725 est un peu surestimé, mais « de peu » : pour les deux premiers livres, j’ai exactement 2.5 comparaisons de trop ; pour les autres, j’ai au pire 0.5 comparaisons de trop. Sur 100 livres, ça fait donc au plus 98*0.5 + 2.5 = 51.5 opérations comptées en trop ; mon nombre exact d’opérations est donc compris entre 2673 et 2725. Il y aurait moyen de faire les choses un peu plus précisément, mais on verra par la suite (dans le prochain billet) pourquoi ça n’a pas grand intérêt.
Si je compte pour n livres, j’arrive à une estimation de (n*(n+1)/2)/2 + 2*n = (n²+9n)/4 opérations.
On peut montrer (mais pour le coup ça prendrait vraiment des proportions ici) que ce comportement est à peu près celui qu’on a quand on a des livres dans un ordre aléatoire. L’idée, c’est que si mes livres sont dans un ordre aléatoire, je vais en insérer certains plutôt au début, d’autres plutôt à la fin, et donc, « en moyenne », à peu près au milieu.
Une autre méthode de tri
Je vais maintenant expliquer une autre méthode de tri, qui est probablement moins facile à conceptualiser, mais qui je pense est la méthode la plus simple qui me permet de continuer mon argument.
Je vais supposer, cette fois, que je n’ai pas 100 livres à trier, mais 128. Parce que c’est une puissance de 2 et que ça me facilite la vie pour mon exemple concret. Et parce que j’y ai pas pensé avant et que j’ai la flemme de remonter dans mon exemple pour repartir sur 128 plutôt que 100.
Je suppose que tous mes livres sont sur la table, directement posés dessus, et je vais faire des « ensembles » avant de ranger mes bouquins dans la bibliothèque. Et je vais faire ces ensembles d’une façon un peu bizarroïde, mais efficace.
Je commence par combiner mes livres deux par deux. Je prends deux livres, je les compare, je mets le plus petit à gauche et le plus grand à droite. À la fin de cette opération, j’ai 64 ensembles de deux livres, avec dans chaque ensemble un petit livre à gauche et un grand livre à droite. Pour faire cette opération, j’ai dû faire, en tout, 64 comparaisons, et 128 déplacements de livres (je suppose que je déplace toujours les livres, ne serait-ce que pour les prendre en main et lire les auteurs/titres).
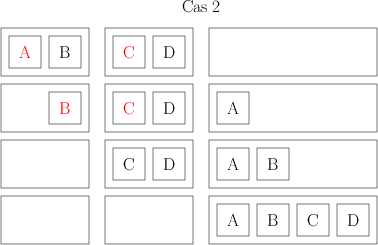
Ensuite, je prends mes ensembles de deux livres, et je les combine aussi de façon à avoir des ensembles de 4 livres, toujours ordonnées. Pour faire ça, je compare les deux premiers livres de deux ensembles, le plus petit des deux devient le premier livre de mon nouvel ensemble de 4. Je compare ensuite le livre restant de l’ensemble de 2 avec le premier livre de l’ensemble de 2, et je mets le plus petit en 2e position de mon ensemble de 4. Là, il peut se passer deux choses. Ou bien il me reste un livre dans chacun des ensembles initiaux ; auquel cas, je les compare, et je les mets dans l’ordre dans mon ensemble de 4. Ou bien il me reste un ensemble de deux ; je peux alors me contenter de les ajouter à la fin de mon ensemble de 4 et j’ai mon ensemble de 4. Voilà deux petits dessins qui distinguent les deux cas ; chaque carré représente un livre dont l’auteur a un nom commençant par la lettre indiquée, chaque rectangle représente mes ensembles de livres (les initiaux de 2 et le final de 4 livres), et les éléments rouges sont ceux qui sont comparés à chaque étape.
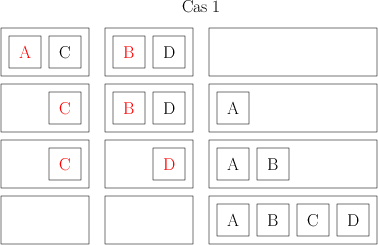
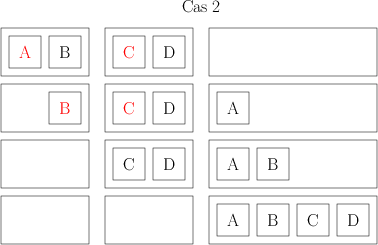
Bref, pour chaque ensemble de 4 que je crée, je dois faire 4 déplacements, et 2 ou 3 comparaisons. Je termine cette opération avec 32 ensembles de 4 livres ; donc au final je fais 32*4 = 128 déplacements et entre 32*2 = 64 et 32*3 = 96 comparaisons.
Je crée ensuite 16 ensembles de 8 livres, également en comparant le premier élément de chaque ensemble de livres et en créant un ensemble commun trié. Pour combiner deux ensembles de 4, il me faut 8 déplacements et entre 4 et 7 comparaisons. Je ne vais pas rentrer dans le détail de la manière d’obtenir ces chiffres ; la manière la plus simple avec ce genre de chiffres est d’énumérer tous les cas, ça commence à être fastidieux à 4, mais c’est encore gérable. Donc pour créer les 16 ensembles de 8 livres, il faut que je fasse 16*8 = 128 déplacements et entre 16*4 = 64 et 16*7 = 112 comparaisons.
Et je continue comme ça jusqu’à avoir 2 ensembles de 64 livres, que je finis par combiner (directement dans la bibliothèque pour gagner du temps) pour obtenir une bibliothèque rangée.
Bon, et combien de temps ça me prend cette affaire ? Je vais déjà commencer par donner une estimation pour 128 livres, et après je regarderai ce que ça donne pour n livres. Le plus pénible, ça ne surprendra personne, est d’évaluer le nombre de comparaisons quand on combine deux ensembles de livres. Je vais me permettre une approximation de plus pour dire que, si je veux combiner deux ensembles qui font chacun k éléments en un gros ensemble qui fait 2*k éléments, il me faut au plus 2*k comparaisons. Pour voir ça, on peut essayer de raisonner par énumération et faire une preuve propre et tout. J’avoue que j’ai pas le courage, d’autant plus que je sais où mon raisonnement va, et que je sais que j’ai pas envie de faire des calculs précis, parce qu’au final c’est pas très important d’être précis. On peut aussi faire l’observation suivante : à chaque fois qu’on fait une comparaison, on pose un bouquin dans le « gros » ensemble. Comme je ne pose que 2*k livres, je ne peux pas faire plus de 2*k comparaisons : si je faisais, par exemple, 2*k+1 comparaisons, il faudrait que je pose 2*k+1 livres… et je ne les ai pas. Donc, je vais estimer qu’à chaque fois que je combine deux ensembles de k éléments chacun en un ensemble de 2*k éléments, je fais au maximum 2*k comparaisons, et que je fais exactement 2*k déplacements. La deuxième observation, pour aller un peu plus loin et gagner encore un peu de temps dans les estimations, c’est qu’à chaque fois que je combine mes ensembles de k éléments en ensembles de 2*k éléments, je pose, en tout, exactement 128 livres (puisque c’est le nombre total de livres que j’ai, que chaque livre est dans un « petit » ensemble au départ et qu’il arrive dans un « grand » ensemble). Donc, je ne fais, au maximum, que 128 comparaisons à chaque étape.
Il me reste donc à compter le nombre d’étapes.
Pour 128 livres, ça me fait donc, au maximum :
- Passer de 128 ensembles de 1 à 64 ensembles de 2
- Passer de 64 ensembles de 2 à 32 ensembles de 4
- Passer de 32 ensembles de 4 à 16 ensembles de 8
- Passer de 16 ensembles de 8 à 8 ensembles de 16
- Passer de 8 ensembles de 16 à 4 ensembles de 32
- Passer de 4 ensembles de 32 à 2 ensembles de 64
- Passer de 2 ensembles de 64 à 1 ensemble de 128
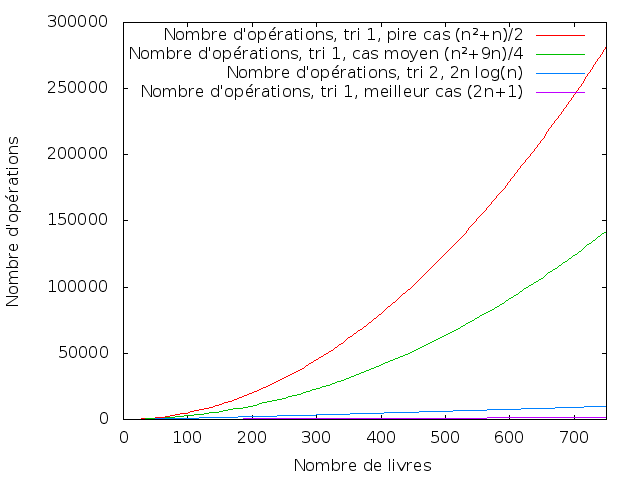
Soit 7 étapes. Dans chacune de ces 7 étapes, j’ai 128 déplacements, et au maximum 128 comparaisons, soit au maximum 7*(128+128) = 1792 opérations. Notons que je n’ai fait ici aucune hypothèse sur l’ordre initial des livres. À comparer avec les 5050 opérations du « pire cas » du tri précédent, ou avec les environ 2700 opérations du cas « moyen » – nombres qui étaient d’ailleurs calculés pour 100 livres et pas 128 - pour 128 livres, on aurait, respectivement, 8256 opérations pour le « pire cas » et environ 4300 opérations pour le cas moyen.
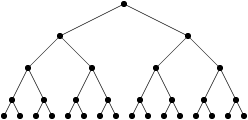
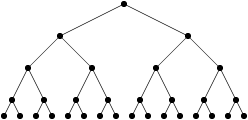
Qu’en est-il exactement de la formule générale pour n livres ? Je pense qu’on peut être d’accord sur le fait que, à chaque étape, on déplace n livres, et qu’on fait au plus n comparaisons (puisque chaque comparaison correspond au fait de poser un livre). Donc, à chaque étape, je fais au plus 2*n comparaisons. La question est maintenant de savoir combien d’étapes on fait. Et c’est ici que mon splendide billet sur les logarithmes (kof) m’est utile. Est-ce que vous pouvez voir la similarité avec la figure suivante ?

Et si je dis que les feuilles de l’arbre sont les livres en bordel avant la première étape ? C’est plus clair ? (J’espère…). Au niveau d’au-dessus, les feuilles (livres) sont combinées en ensembles de deux, qu’on combine au niveau d’au-dessus en ensembles de quatre, etc… jusqu’à n’avoir qu’un seul ensemble qui contient tous les livres. Et le nombre d’étapes est précisément égal au logarithme (en base 2) du nombre de livres, ce qui correspond à la « profondeur » (le nombre de niveaux) de l’arbre en question.
Donc, pour conclure, pour n livres, j’ai, dans le modèle que j’ai défini, 2*n*log(n) opérations (où mon log est en base 2).
Voilà, je vais arrêter là pour ce premier billet. Dans le billet suivant, j’expliquerai pourquoi je ne me suis pas trop fatiguée à faire des calculs complètement exacts et pourquoi la phrase que je prononce probablement le plus souvent c’est « pff, c’est une constante, on s’en fout ». (Et peut-être aussi pourquoi des fois on s’en fout pas tant que ça 🙂 ). J’espère que c’était à peu près compréhensible jusqu’ici ; sinon, n’hésitez pas à râler, poser des questions, et tout ce genre de choses. Moi en tous cas je trouve ça rigolo d’écrire tout ça 🙂
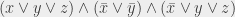



, sinon
(
prend la valeur inverse de x)
; si y = 1 alors
(« x OU y vaut 1 »). Il faut préciser que quand on dit « ou » dans ce contexte, ce n’est pas dans le même sens que « fromage ou dessert » : si on prend du fromage et du dessert, alors on prend du fromage ou du dessert (puisqu’on prend au moins l’un des deux).
, sinon
(« x ET y valent tous les deux 1 »).



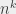 , avec n représentant la taille de l’entrée, et k représentant un nombre quelconque (y compris de très grands nombres, tant qu’ils ne dépendent pas de n lui-même). Le nom vient du fait que les fonctions de type
, avec n représentant la taille de l’entrée, et k représentant un nombre quelconque (y compris de très grands nombres, tant qu’ils ne dépendent pas de n lui-même). Le nom vient du fait que les fonctions de type 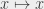 ,
, 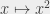 ,
,  et
et  s’appellent des fonctions polynomiales. Comme je peux trier des éléments en temps n² (et même n log n, ce qui est « mieux »), le tri est résolu en temps polynomial. Ça marcherait aussi si je pouvais trier des éléments en temps n⁴⁷⁹, ça serait aussi polynomial. L’énorme avantage des polynômes, c’est que ça se combine vachement bien. Si je fais deux opérations polynomiales, je reste en temps polynomial. Si je fais un nombre polynomial d’opérations polynomiales, je reste en temps polynomial. Mon polynôme « grossit » (il passe par exemple de n² à n⁵), mais il reste un polynôme.
s’appellent des fonctions polynomiales. Comme je peux trier des éléments en temps n² (et même n log n, ce qui est « mieux »), le tri est résolu en temps polynomial. Ça marcherait aussi si je pouvais trier des éléments en temps n⁴⁷⁹, ça serait aussi polynomial. L’énorme avantage des polynômes, c’est que ça se combine vachement bien. Si je fais deux opérations polynomiales, je reste en temps polynomial. Si je fais un nombre polynomial d’opérations polynomiales, je reste en temps polynomial. Mon polynôme « grossit » (il passe par exemple de n² à n⁵), mais il reste un polynôme.


 . Ou même en
. Ou même en  . Ou même en
. Ou même en  .
.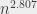 (ce qui est meilleur que le n³). Et en se forçant beaucoup, il existe un algorithme qui fonctionne en temps
(ce qui est meilleur que le n³). Et en se forçant beaucoup, il existe un algorithme qui fonctionne en temps 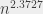 (Coppersmith–Winograd et ses dérivés). C’est, je crois, le seul algorithme pour lequel j’ai entendu PLUSIEURS personnes faisant de la théorie dire que « oui, mais vraiment, la constante est vraiment dégueulasse » - en parlant du nombre par lequel on multiplie ce
(Coppersmith–Winograd et ses dérivés). C’est, je crois, le seul algorithme pour lequel j’ai entendu PLUSIEURS personnes faisant de la théorie dire que « oui, mais vraiment, la constante est vraiment dégueulasse » - en parlant du nombre par lequel on multiplie ce 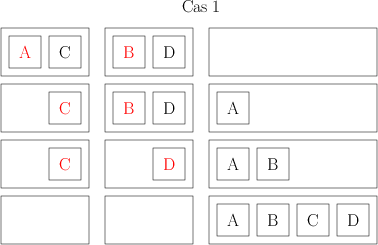
 , où
, où 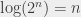

 . Et, bon, ben de la même manière, je peux définir un logarithme qui soit la réciproque de ce
. Et, bon, ben de la même manière, je peux définir un logarithme qui soit la réciproque de ce 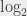 ,
, 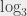
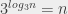

 ,
,  (parce que
(parce que  ); tous les nombres entre 10 et 100 ont un logarithme en base 10 entre 1 et 2. De la même manière, on peut estimer que le logarithme en base 10 de 14578 est entre 4 et 5. Pour voir ça, il suffit de voir que 14578 est compris entre
); tous les nombres entre 10 et 100 ont un logarithme en base 10 entre 1 et 2. De la même manière, on peut estimer que le logarithme en base 10 de 14578 est entre 4 et 5. Pour voir ça, il suffit de voir que 14578 est compris entre  et
et  , ce qui permet de conclure sur la valeur du logarithme. (Je passe un certain nombre de choses sous le tapis ici, en particulier les raisons qui font qu’on peut effectivement conclure ça.)
, ce qui permet de conclure sur la valeur du logarithme. (Je passe un certain nombre de choses sous le tapis ici, en particulier les raisons qui font qu’on peut effectivement conclure ça.) (qui correspond à la puissance à laquelle j’élève
(qui correspond à la puissance à laquelle j’élève 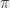 (qui correspond à… bon, ça ira, peut-être) si ça me chante. C’est moins « intuitif » si je considère mon explication avec les arbres et le nombre de niveaux (parce que c’est difficile de faire
(qui correspond à… bon, ça ira, peut-être) si ça me chante. C’est moins « intuitif » si je considère mon explication avec les arbres et le nombre de niveaux (parce que c’est difficile de faire  . Le logarithme népérien est un logarithme en base
. Le logarithme népérien est un logarithme en base  . On peut exprimer n’importe quel logarithme dans n’importe quelle base
. On peut exprimer n’importe quel logarithme dans n’importe quelle base  comme ceci :
comme ceci :
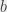 comme ça :
comme ça :

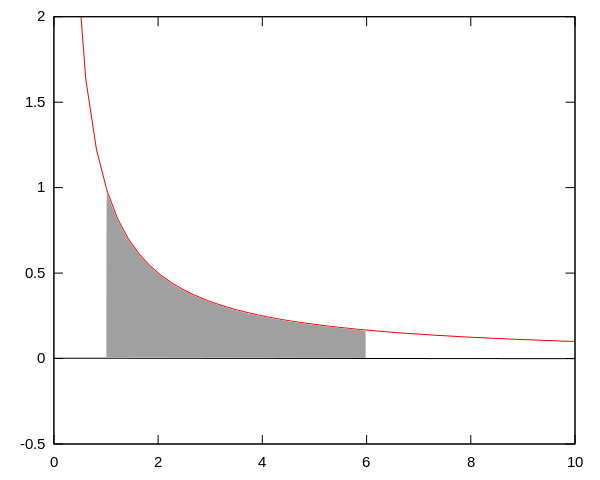
 . La zone grise correspond ici à l’intégrale de 1 à 6 ; l’aire de cette zone est égale à ln(6). Et on peut représenter le logarithme népérien de n’importe quelle valeur (supérieure à 1) par l’aire de la surface située entre l’axe des
. La zone grise correspond ici à l’intégrale de 1 à 6 ; l’aire de cette zone est égale à ln(6). Et on peut représenter le logarithme népérien de n’importe quelle valeur (supérieure à 1) par l’aire de la surface située entre l’axe des  et la courbe
et la courbe