Dans un billet précédent, j’ai tenté d’expliquer avec brio (je vous laisse choisir le verbe qualifié par « avec brio ») le problème « P = NP ». J’y ai donné une définition de la classe NP, que je répète ici : NP est la classe des problèmes pour lesquels, pour chaque instance de type « oui », on peut me convaincre en temps polynomial que la réponse est « oui » en me fournissant une preuve que c’est effectivement le cas. Et en fin de billet, j’ai vaguement mentionné la notion de problème NP-complet.
La définition usuelle de problème NP-complet, c’est un problème qui est « dans NP » et « NP-difficile ». Je vais donc expliquer ce que veut dire NP-difficile 🙂 De façon informelle, c’est un problème qui est au moins aussi difficile que tous les problèmes de la classe NP. Une autre façon informelle de dire ça, c’est qu’il est aussi difficile qu’un autre problème NP-difficile. Le problème de cette définition, c’est qu’il faut bien commencer quelque part, et avoir un premier problème NP-difficile pour le comparer aux autres.
L’archétype des problèmes NP-difficiles (et donc NP-complets, parce que SAT est dans NP), c’est le problème SAT, dont j’ai parlé dans le billet précédent. C’est pas évident, a priori, que SAT est NP-difficile. Mais on peut montrer que même 3-SAT est NP-difficile : 3-SAT représente les instances de SAT où toutes les clauses ont exactement trois littéraux ((Les avis diffèrent sur la terminologie exacte. De nombreux auteurs définissent 3-SAT comme les instances de SAT où toutes les clauses ont au plus deux littéraux. J’appelle ça (sur la suggestion de mon prof de SAT) <=3-SAT. Dans le cas présent ça m’arrange de définir sur exactement 3 littéraux, donc je fais ça, OK ?)). Je ne vais en pas expliquer la preuve, parce que ça impliquerait que je passe pas mal de temps à expliquer des choses que j’ai pas fondamentalement envie d’expliquer. Pour les gens intéressés par la question, ça a été démontré en 1971 et c’est connu sous le nom de Théorème de Cook-Levin.
Maintenant qu’on en a un, on peut en trouver d’autres par réduction. On réduit un problème NP-difficile (par exemple SAT) à un autre problème qu’on veut prouver NP-difficile, appelons le A. Pour faire ça, on démontre que si on peut résoudre A efficacement, c’est-à-dire en temps polynomial, alors on peut résoudre SAT efficacement.
L’idée générale de ce genre de preuve, c’est qu’on prend une instance quelconque du problème NP-difficile, et on la transforme, en temps polynomial, en instance du problème A qui permette de conclure sur l’instance originale. Maintenant, supposons qu’on sache résoudre le problème A (c’est-à-dire n’importe quelle instance du problème A) en temps polynomial. Alors on peut prendre n’importe quelle instance de SAT, la transformer en une instance du problème A, résoudre l’instance du problème A, et conclure. La transformation se fait en temps polynomial, la résolution de A se fait en temps polynomial, la somme des deux est polynomiale, donc on sait résoudre n’importe quelle instance de SAT en temps polynomial, donc on sait résoudre SAT en temps polynomial. Facile.
Les problèmes NP-complets sont donc, en quelque sorte, « équivalents » en terme de complexité : si on sait en résoudre un en temps polynomial, alors on peut résoudre tous les autres en temps polynomial aussi, et on peut résoudre tous les problèmes de NP en temps polynomial (puisqu’ils sont aussi difficiles que tous les problèmes de la classe NP). Donc, si on trouve un moyen de résoudre en temps polynomial toutes les instances d’un problème NP-complet… on a démontré que P = NP. Et gagné un million de dollars. Et surpris beaucoup, beaucoup de monde.
Il y a toute une série de problèmes pour lesquels on sait qu’ils sont NP-difficiles, ou NP-complets si en plus ils sont dans NP. Il y a des gens qui s’intéressent à des problèmes… exotiques, dirons-nous ; je vais juste laisser quelques liens pour les gens intéressés et que ça fera rigoler :
Passé cet interlude amusant, je vais donner un exemple de réduction pour prouver que le problème CLIQUE est NP-complet. C’est probablement l’exemple bateau que tout le monde donne quand il parle de ce genre de chose, mais il doit y avoir une raison à ça (la raison en est que le problème est raisonnablement facile à décrire et que la réduction est relativement simple par rapport à ce qu’on peut voir ailleurs). Le truc que j’explique ici est largement repompé du CLRS, c’est-à-dire le Cormen, Leiserson, Rivest & Stein, c’est-à-dire Introduction to Algorithms, traduit en français sous le nom Algorithmique (je ne sais pas ce que vaut cette traduction) – c’est le bouquin de référence de BEAUCOUP de cours d’algorithmique.
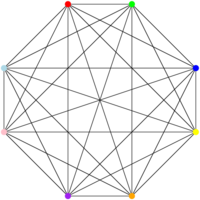
Donc, le problème CLIQUE est le suivant : étant donné un graphe (un ensemble de sommets et d’arcs) G, contient-il une clique de taille k ? Une clique de taille k, c’est un ensemble de k sommets qui sont tous reliés les uns aux autres. Par exemple (vous m’excuserez, je recycle mes figures), ce machin-là est est une clique de taille 8. Notons au passage qu’il contient également une clique de taille 1 (un seul sommet), 2 (un arc), 3 (un triangle), 4, 5, 6 et 7, puisqu’on peut trouver des ensembles de sommets de cette taille qui sont tous reliés les uns aux autres.
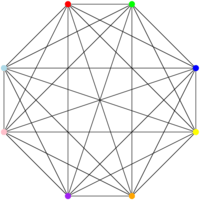
On veut réduire 3-SAT à ce problème ; comme 3-SAT est NP-difficile, CLIQUE est NP-difficile aussi. CLIQUE est dans NP, parce que si je donne k sommets, c’est facile de vérifier que ces k sommets sont effectivement tous reliés les uns aux autres. Donc, si CLIQUE est NP-difficile, CLIQUE est NP-complet.
Pour attaquer ma réduction, je prends une formule 3-SAT. Je prends une formule 3-SAT CNF (j’ai expliqué ce que ça veut dire dans mon article sur SAT), c’est-à-dire une formule qui a cette tête là :
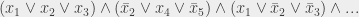
c’est-à-dire un ensemble de m clauses composées d’au plus 3 littéraux reliés par des OU, et les clauses étant reliées par des ET.
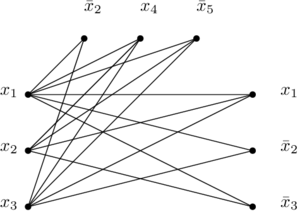
À partir de là, on crée un graphe contenant 3*m sommets. Chacun de ces sommets correspond à un littéral de la formule, éventuellement dupliqué. Pour visualiser les choses plus facilement, ça peut peut-être aider de grouper les sommets en groupes de trois. Dans l’exemple de la formule ci-dessus, ça donne les sommets suivants :

Ensuite, on ajoute des arcs partout. Enfin, presque partout. On n’ajoute pas d’arcs dans les « groupes » correspondant aux clauses. On n’ajoute pas non plus d’arcs entre les littéraux qui ne sont pas « compatibles », c’est-à-dire l’inverse l’un de l’autre. Si j’ai deux littéraux  et
et  , je ne crée pas d’arc entre eux. Pour ma mini-formule au-dessus, voilà ce que donne le graphe en question :
, je ne crée pas d’arc entre eux. Pour ma mini-formule au-dessus, voilà ce que donne le graphe en question :
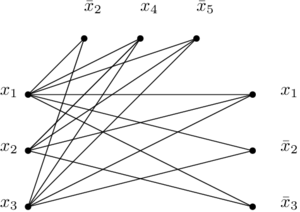
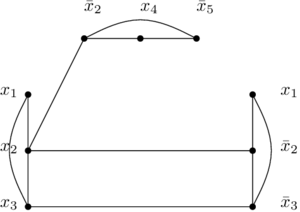
et voilà les arcs qui ne sont PAS dans le graphe précédent :
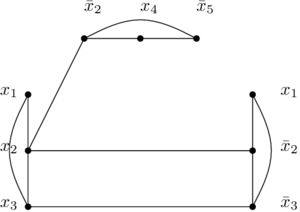
Et maintenant qu’on a ce graphe là, l’idée, c’est que la formule SAT peut être satisfaite si et seulement si le graphe (le premier) a une clique de taille m (m étant le nombre de clauses de la formule SAT). J’ai donc deux choses à prouver :
- si la formule peut être satisfaite, alors le graphe a une clique de taille m
- si le graphe a une clique de taille m, la formule peut être satisfaite.
On va commencer par le premier point. Supposons que la formule puisse être satisfaite. Donc, on peut affecter une valeur à toutes les variables de sorte que la formule soit satisfaite. Par conséquent, toutes les clauses peuvent être satisfaites par cette affectation. Donc, dans chaque clause, il existe un littéral qui a pour valeur 1 (le littéral « positif », par exemple si la variable a la valeur 1, le littéral « négatif », par exemple si la variable a la valeur 0). On considère, dans chaque « groupe » de sommets du graphe défini précédemment, le sommet correspondant à ce littéral (si plusieurs littéraux ont la valeur 1, on en prend un au pif). Comme on prend un sommet par groupe, et qu’on a m groupes, on arrive à m sommets. On veut maintenant montrer qu’il y a un arc entre toutes les paires de sommets de cet ensemble de sommets. Or, les deux raisons pour lesquelles on pourrait ne pas en avoir, c’est soit que les sommets sont dans le même groupe, soit qu’ils sont incompatibles. On ne peut pas avoir choisi deux sommets dans le même groupe, puisqu’on en a choisi exactement un par groupe. Et on ne peut pas avoir choisi deux sommets incompatibles, parce qu’ils correspondraient à des littéraux  et
et  , qu’on n’a choisi que des littéraux qui ont la valeur 1, et qu’on ne peut pas avoir en même temps
, qu’on n’a choisi que des littéraux qui ont la valeur 1, et qu’on ne peut pas avoir en même temps  et
et 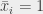 . Donc, toutes les paires dans les m sommets sont connectées entre elles, donc on a une clique de taille m, ce qu’on voulait démontrer.
. Donc, toutes les paires dans les m sommets sont connectées entre elles, donc on a une clique de taille m, ce qu’on voulait démontrer.
Donc, on peut passer au deuxième point : si le graphe a une clique de taille m, la formule peut être satisfaite. Supposons, donc, que le graphe ait une clique de taille m. Comme les sommets d’un même groupe ne sont pas connectés entre eux, les sommets sont forcément dans des groupes différents. Si on a une clique de taille m, ça veut dire qu’on a un sommet dans chaque groupe de sommets. On peut donner à tous ces sommets la valeur 1. On ne peut pas avoir de clique qui contienne des sommets et , puisqu’il n’y a pas d’arc entre deux sommets de ce type et que, par définition d’une clique, il faut que tous les arcs soient présents. Donc, si une clique de taille m existe, ça veut dire qu’on a trouvé un littéral par clause qui peut valoir 1, et que tous ces littéraux sont compatibles entre eux. Et donc qu’on peut satisfaire la formule correspondant au graphe, ce qu’on voulait démontrer aussi.
Donc, si on peut résoudre CLIQUE en temps polynomial, alors on peut résoudre SAT en temps polynomial ; SAT étant NP-difficile, CLIQUE l’est aussi, et donc CLIQUE est NP-complet, ce qui termine la preuve.
Le caractère NP-complet d’un problème est, quelque part, une « preuve » de la difficulté du problème en question, mais il faut atténuer ça largement. Déjà, ça ne présume en rien de la difficulté d’une instance donnée du problème. Ça ne présume en rien de la difficulté sur une certaine classe d’instances non plus. J’explique. Dire que CLIQUE est difficile, ça ne veut pas dire que, par exemple, décider si un triangle (qui est une clique de taille 3) est dans un graphe, même un gros graphe, est difficile. Parce que je peux prendre tous les ensembles de trois sommets, regarder s’ils forment un triangle, et conclure. Les ensembles de trois sommets, il y en a à peu près n³ dans un graphe à n sommets (plus exactement, il y en a n(n-1)(n-2)/6, mais, bon, à peu près n³), du coup je peux décider ça en temps polynomial (je fais n³ opérations qui vont pas prendre des plombes, c’est-à-dire vérifier si trois arcs donnés sont effectivement dans le graphe). Du coup, je peux décider 3-CLIQUE en temps polynomial. Bon, c’est pas pour ça que je vais être millionnaire, hein. Parce que le problème CLIQUE, il se limite pas à 3. Cela dit, si je veux, je peux aussi décider 1000-CLIQUE (clique de taille 1000) en temps polynomial. Bon, c’est un polynôme de degré 1000, mais on s’en fout 🙂
Par contre, dans le cas général, je ne peux pas décider si un graphe sur n sommets contient une clique de n/2 sommets, ou n/10000 sommets, ou même log n sommets en temps polynomial avec cet algorithme qui regarde tous les groupes de taille k (donc ici k = n/2, n/10000 ou log n) et qui regarde les arcs dans le groupe, parce que ça impliquerait de faire respectivement à peu près  et
et  opérations, et que dans tous les cas c’est pas polynomial. Et, de manière générale, personne ne sait si c’est possible de faire ça en temps polynomial, puisque CLIQUE est NP-complet et qu’on ne sait pas si P est égal à NP. Beaucoup de gens supposent que non, mais personne ne sait.
opérations, et que dans tous les cas c’est pas polynomial. Et, de manière générale, personne ne sait si c’est possible de faire ça en temps polynomial, puisque CLIQUE est NP-complet et qu’on ne sait pas si P est égal à NP. Beaucoup de gens supposent que non, mais personne ne sait.
Même là, ça ne présume en rien de la difficulté d’une instance donnée d’un problème. Supposons qu’on me file un graphe qui se trouve contenir n(n-1)/2 arcs pour n sommets. Alors je peux décider, sans trop de problème, que oui, ce graphe contient une clique de taille n/2, n/10000 et log n. Parce qu’un graphe de n(n-1)/2 arcs pour n sommets, ben il contient tous les arcs possibles pour le graphe : c’est un graphe complet (une clique sur n sommets), et comme une clique sur k sommets est un sous-graphe d’une clique sur n sommets… ben c’est pas bien difficile de répondre à la question. Idem si on me file un graphe avec 0 arcs et n sommets, je vais pas avoir beaucoup de mal à répondre que non, il ne contient pas de clique de taille n/2.
Dans le cas de SAT, on n’a aucun problème à résoudre les instances de 2-SAT (où toutes les clauses contiennent deux littéraux) en temps polynomial (et même linéaire). Il y a aussi des instances de SAT qui sont « faciles », par exemple celles où il y a peu de dépendances entre les clauses : on sait qu’on peut les résoudre, et on sait même comment (et, pour les gens intéressés, par « peu de dépendances », j’entends « qui tombent dans le cas du Lovász local lemma, dont l’application à SAT n’est pas évidente d’après la définition de la Wikipedia, mais qui devrait être plus claire ici).
De manière générale, il peut même être non trivial de créer des instances de problèmes NP-complets qu’on ne sait pas résoudre en temps polynomial. Notons au passage que c’est pas facile de prouver qu’on ne sait pas résoudre une instance donnée en temps polynomial. On peut exhiber des instances de problèmes qui sont difficiles (i.e. exponentielles) pour un algorithme donné, et triviales pour d’autres algorithmes…
Et c’est un peu ce qui se passe en pratique : on a des instances de problèmes pour lesquels on sait que le cas général est NP-complet (ou pire), et qu’on résout pourtant tous les jours en pratique. Une des raisons peut être que le problème est « petit » (c’est pas un drame de coller un algorithme exponentiel sur un problème de taille 4, quoi), mais ça peut aussi être parce que le problème fait partie d’une sous-classe d’instances sur laquelle le problème est facile. Donc, conclure qu’une instance de problème est difficile parce que le problème général l’est et abandonner (parce qu’on saura pas faire), c’est pas forcément une bonne idée, parce qu’il se peut qu’on n’ait pas considéré qu’on se trouve dans une restriction facile du problème !
Bref, comme d’habitude, « c’est pas aussi simple que ça ». En ce moment, je fais de la théorie, et du coup je m’intéresse plutôt aux problèmes eux-mêmes plutôt qu’à des instances données. Mais c’est parfois salutaire de se souvenir que des trucs « difficiles en théorie » peuvent s’avérer « faciles en pratique », ça change des trucs faciles en théorie qu’on sait pas faire en pratique… 🙂



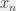





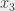





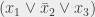
sur
est trivialement idiot, on affecte 1 à




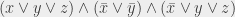
 , ça veut dire « ou », et
, ça veut dire « ou », et  , ça veut dire « et ». Les petites barres au-dessus de certaines lettres indiquent un négation. Les symboles se lisent comme ça :
, ça veut dire « et ». Les petites barres au-dessus de certaines lettres indiquent un négation. Les symboles se lisent comme ça :
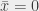 , sinon
, sinon 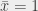 (
( prend la valeur inverse de x)
prend la valeur inverse de x)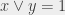 ; si y = 1 alors
; si y = 1 alors 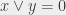 (« x OU y vaut 1 »). Il faut préciser que quand on dit « ou » dans ce contexte, ce n’est pas dans le même sens que « fromage ou dessert » : si on prend du fromage et du dessert, alors on prend du fromage ou du dessert (puisqu’on prend au moins l’un des deux).
(« x OU y vaut 1 »). Il faut préciser que quand on dit « ou » dans ce contexte, ce n’est pas dans le même sens que « fromage ou dessert » : si on prend du fromage et du dessert, alors on prend du fromage ou du dessert (puisqu’on prend au moins l’un des deux). 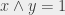 , sinon
, sinon  (« x ET y valent tous les deux 1 »).
(« x ET y valent tous les deux 1 »). ) tous reliés entre eux par des symboles
) tous reliés entre eux par des symboles 


