Aujourd’hui, on va causer 3-SAT, et on va en particulier causer de deux algorithmes très voisins, les algorithmes PPZ et son petit frère PPSZ.
Il est plus que temps que je m’attaque à ce billet que j’aurais dû écrire depuis longtemps déjà. C’est un billet qui me tient à cœur parce que ça fait un an et demi que je fais des trucs autour de ces algorithmes, et que je commence à en avoir une assez bonne idée 🙂
Rappelons un peu de formalisme, histoire qu’on sache tous de quoi on est en train de parler. Pour une intro avec un peu plus de détails, voir mon billet sur SAT. J’ai  variables
variables  , et j’ai des formules qui sont de ce type:
, et j’ai des formules qui sont de ce type:

et je veux déterminer si, étant donné une telle formule, il existe des valeurs pour les variables  à
à 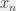 (on parle d’une affectation) qui permettent d’évaluer la formule à 1 (on dit alors que la formule est satisfaite). Dans le cas général, c’est un problème NP-complet ; on a donc peu de chance de trouver un algorithme efficace qui marche à tous les coups. C’est bien le « à tous les coups » qui m’intéresse ici : je me demande ce que je peux garantir pour mon algorithme, même si je tombe sur la formule la plus difficile du monde. Le « record » actuel pour ce type de garantie est actuellement pour l’algorithme PPSZ, qui est un algorithme aléatoire, et qui est le sujet de ce billet. Comme je parle d’algorithme aléatoire, il me paraît un poil plus intuitif de parler de probabilité de succès que de temps d’exécution même si, on l’a vu, les deux notions sont liées – puisqu’il suffit de répéter un algorithme aléatoire avec une probabilité de succès donnée suffisamment de fois pour être raisonnablement sûr qu’il réussisse. Ça fait un peu Shadok, mais passons. Je vais aussi, dans ce qui suit, supposer que j’ai une formule pour laquelle je sais qu’il existe un ensemble de valeurs qui la satisfont, et que je veux « juste » trouver les valeurs en question. En pratique, les deux problèmes sont liés aussi : je peux supposer que si mon algorithme trouve ces valeurs, ben c’est qu’elles existent, et que si je cherche suffisamment longtemps sans les trouver, ça serait quand même pas de bol qu’elles existent et que je les aie ratées.
(on parle d’une affectation) qui permettent d’évaluer la formule à 1 (on dit alors que la formule est satisfaite). Dans le cas général, c’est un problème NP-complet ; on a donc peu de chance de trouver un algorithme efficace qui marche à tous les coups. C’est bien le « à tous les coups » qui m’intéresse ici : je me demande ce que je peux garantir pour mon algorithme, même si je tombe sur la formule la plus difficile du monde. Le « record » actuel pour ce type de garantie est actuellement pour l’algorithme PPSZ, qui est un algorithme aléatoire, et qui est le sujet de ce billet. Comme je parle d’algorithme aléatoire, il me paraît un poil plus intuitif de parler de probabilité de succès que de temps d’exécution même si, on l’a vu, les deux notions sont liées – puisqu’il suffit de répéter un algorithme aléatoire avec une probabilité de succès donnée suffisamment de fois pour être raisonnablement sûr qu’il réussisse. Ça fait un peu Shadok, mais passons. Je vais aussi, dans ce qui suit, supposer que j’ai une formule pour laquelle je sais qu’il existe un ensemble de valeurs qui la satisfont, et que je veux « juste » trouver les valeurs en question. En pratique, les deux problèmes sont liés aussi : je peux supposer que si mon algorithme trouve ces valeurs, ben c’est qu’elles existent, et que si je cherche suffisamment longtemps sans les trouver, ça serait quand même pas de bol qu’elles existent et que je les aie ratées.
L’algorithme aléatoire le plus simple auquel on peut penser est de prendre des valeurs au hasard, de vérifier si elles satisfont la formule, et de recommencer si c’est pas le cas. Toutes les affectations possibles ont la même probabilité (si je les choisis au hasard comme ça) – et j’en ai  – parce que pour chaque variable, j’ai deux possibilités, 0 ou 1. Donc la probabilité de succès de cet algorithme, si j’ai
– parce que pour chaque variable, j’ai deux possibilités, 0 ou 1. Donc la probabilité de succès de cet algorithme, si j’ai  affectations qui satisfont ma formule, est de
affectations qui satisfont ma formule, est de  : parmi les choix que je peux faire, j’en ai qui marchent.
: parmi les choix que je peux faire, j’en ai qui marchent.
Après, il y a moyen de faire les choses de manière un peu plus intelligente. Plutôt que d’affecter les variables toutes en même temps, je vais les affecter une à une. Qu’est-ce que ça change ? Ça change que si j’ai un truc qui est trivialement idiot à faire, je peux éviter de le faire. Ce qui veut dire qu’il faut que j’explique ce que ça veut dire « trivialement idiot ». Supposons que j’aie une formule très simple qui soit juste  . Si j’ai choisi pour la valeur 0 et pour
. Si j’ai choisi pour la valeur 0 et pour  la valeur 0, il est « trivialement idiot » de choisir 0 pour
la valeur 0, il est « trivialement idiot » de choisir 0 pour 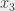 puisque je n’ai alors aucune chance de satisfaire la formule. Donc par « trivialement idiot », je veux dire qu’il y a une clause qu’il n’y a plus qu’une seule chance de satisfaire, c’est-à-dire qu’on a déjà affecté des valeurs à deux variables sur les trois de la clause, et que la clause n’est toujours pas satisfaite. Si j’utilise mon algorithme précédent, j’ai une probabilité 7/8 de trouver une affectation satisfaisante (parce qu’avec probabilité 1/8 je tombe sur 000 pour mes variables et ma formule n’est pas satisfaite). Si j’essaie d’éviter les trucs trivialement idiots… ben déroulons le truc. Je commence par , il n’y a pas de truc trivialement idiot à éviter, donc je prends une valeur au hasard. Je continue par ; là encore, il n’y a pas de truc trivialement idiot à éviter, donc je prends une valeur au hasard. J’arrive à , et là j’ai deux possibilités. Si et ont été mis tous les deux à 0, j’ai un truc trivialement idiot à éviter, c’est de mettre à 0, donc j’évite ça, je mets à 1, et ma formule est satisfaite. Si ou a été mis à 1, quoi que je fasse sur sera valide, donc je ne peux pas me tromper. Sur ce cas spécifique, rien qu’en évitant les trucs trivialement idiots, mon algorithme passe à une probabilité de succès de 1.
puisque je n’ai alors aucune chance de satisfaire la formule. Donc par « trivialement idiot », je veux dire qu’il y a une clause qu’il n’y a plus qu’une seule chance de satisfaire, c’est-à-dire qu’on a déjà affecté des valeurs à deux variables sur les trois de la clause, et que la clause n’est toujours pas satisfaite. Si j’utilise mon algorithme précédent, j’ai une probabilité 7/8 de trouver une affectation satisfaisante (parce qu’avec probabilité 1/8 je tombe sur 000 pour mes variables et ma formule n’est pas satisfaite). Si j’essaie d’éviter les trucs trivialement idiots… ben déroulons le truc. Je commence par , il n’y a pas de truc trivialement idiot à éviter, donc je prends une valeur au hasard. Je continue par ; là encore, il n’y a pas de truc trivialement idiot à éviter, donc je prends une valeur au hasard. J’arrive à , et là j’ai deux possibilités. Si et ont été mis tous les deux à 0, j’ai un truc trivialement idiot à éviter, c’est de mettre à 0, donc j’évite ça, je mets à 1, et ma formule est satisfaite. Si ou a été mis à 1, quoi que je fasse sur sera valide, donc je ne peux pas me tromper. Sur ce cas spécifique, rien qu’en évitant les trucs trivialement idiots, mon algorithme passe à une probabilité de succès de 1.
C’est pas toujours aussi idyllique, évidemment – là les choses se passent bien parce que j’ai une seule clause, beaucoup d’affectations valides, et qu’on est contents. Maintenant, un cas un peu plus sioux : considérons la formule

Deux affectations satisfont cette formule :  et
et  . Avec mon algorithme « simple », la probabilité de succès est de 2/8 = 1/4. Avec mon algorithme qui cherche à éviter les trucs « trivialement idiots »… aussi, dans certaines conditions. Si je commence par la variable et que je la mets à 0, je n’ai aucune chance d’obtenir une affectation satisfaisant la formule. Si je continue par la variable et que je la mets à 0, idem. Donc il faut que je mette et à 1 tous les deux, ce qui arrive avec une probabilité 1/4 ; peut être mis à n’importe quelle valeur, donc si on n’a pas fait d’erreur jusqu’ici on n’en fera pas non plus à la dernière étape. Dans ce cas, donc, la probabilité de succès avec ou sans la détection de trucs « trivialement idiots » est la même. Sauf que… si on traite les variables non pas dans cet ordre là mais, par exemple, dans l’ordre
. Avec mon algorithme « simple », la probabilité de succès est de 2/8 = 1/4. Avec mon algorithme qui cherche à éviter les trucs « trivialement idiots »… aussi, dans certaines conditions. Si je commence par la variable et que je la mets à 0, je n’ai aucune chance d’obtenir une affectation satisfaisant la formule. Si je continue par la variable et que je la mets à 0, idem. Donc il faut que je mette et à 1 tous les deux, ce qui arrive avec une probabilité 1/4 ; peut être mis à n’importe quelle valeur, donc si on n’a pas fait d’erreur jusqu’ici on n’en fera pas non plus à la dernière étape. Dans ce cas, donc, la probabilité de succès avec ou sans la détection de trucs « trivialement idiots » est la même. Sauf que… si on traite les variables non pas dans cet ordre là mais, par exemple, dans l’ordre  … Pour la première variable, , on ne peut pas faire d’erreur, quelle que soit la valeur d’affectation. Pour , on ne peut pas détecter de truc trivialement idiot, donc on la met à la bonne valeur avec une probabilité 1/2. Mais si cela arrive, la clause
… Pour la première variable, , on ne peut pas faire d’erreur, quelle que soit la valeur d’affectation. Pour , on ne peut pas détecter de truc trivialement idiot, donc on la met à la bonne valeur avec une probabilité 1/2. Mais si cela arrive, la clause  ou la clause
ou la clause 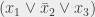 (selon la valeur affectée à ) indiquera à l’algorithme que mettre à 0 est trivialement idiot, ce qu’il faut éviter. Avec cet ordre de variables, la probabilité de succès de notre algorithme amélioré passe à 1/2. Il y a donc de « bons » ordres de variables et de « mauvais » ordres de variables (on parle de permutations). Comme il est difficile de savoir avant de commencer si une permutation est bonne ou mauvaise (ou comment trouver une bonne permutation), on fait comme d’habitude : on prend une permutation au hasard et on espère qu’en moyenne ça marche bien.
(selon la valeur affectée à ) indiquera à l’algorithme que mettre à 0 est trivialement idiot, ce qu’il faut éviter. Avec cet ordre de variables, la probabilité de succès de notre algorithme amélioré passe à 1/2. Il y a donc de « bons » ordres de variables et de « mauvais » ordres de variables (on parle de permutations). Comme il est difficile de savoir avant de commencer si une permutation est bonne ou mauvaise (ou comment trouver une bonne permutation), on fait comme d’habitude : on prend une permutation au hasard et on espère qu’en moyenne ça marche bien.
C’est exactement ce que fait l’algorithme PPZ (nommé d’après ses trois auteurs, Ramamohan Paturi, Pavel Pudlák et Francis Zane, dans un papier intitulé Satisfiability Coding Lemma) :
- On part d’une formule
 sur variables, et on commence avec une affectation vide (on n’affecte aucune valeur aux variables pour l’instant).
sur variables, et on commence avec une affectation vide (on n’affecte aucune valeur aux variables pour l’instant).
- On choisit un ordre aléatoire pour les variables, et on les traite une par une dans cet ordre :
- Pour la variable courante
 , si
, si  est trivialement idiot, on affecte 1 à
est trivialement idiot, on affecte 1 à
- Sinon, si
 est trivialement idiot, on affecte 0 à
est trivialement idiot, on affecte 0 à
- Sinon, on affecte une valeur aléatoire à
- Et on passe à la variable suivante.
- Si l’affectation qu’on trouve satisfait la formule, c’est terminé ! Sinon, on recommence au départ.
L’analyse de la probabilité de succès de l’algorithme est relativement simple. Sans rentrer dans les détails, l’idée c’est que si je n’ai pas le choix pour une variable (c’est-à-dire si la mettre à 0 ou à 1 fait que l’affectation ne peut pas être satisfaisante), alors j’ai au moins une clause qui rend ce choix trivialement idiot dans au moins une permutation sur trois (parce que dans un cas sur trois, la variable en question arrivera en dernier dans la clause en question). J’ai toujours des choix aléatoires pour certaines variables, donc l’algorithme peut toujours se vautrer lamentablement, mais la probabilité de ne pas se vautrer est meilleure que si on prend juste une affectation au hasard.
Après, le lecteur attentif se sera peut-être dit « ouiiii mais si j’assigne à 1, j’ai à la fois une clause  et une clause
et une clause  , donc quelque part c’est AUSSI trivialement idiot de mettre à 0… ». Le lecteur attentif est un petit malin. Et c’est aussi, quelque part, ce que fait l’algorithme PPSZ (nommé d’après les trois auteurs précédents + Michael Saks, dans un papier intitulé An Improved Exponential-Time Algorithm for
, donc quelque part c’est AUSSI trivialement idiot de mettre à 0… ». Le lecteur attentif est un petit malin. Et c’est aussi, quelque part, ce que fait l’algorithme PPSZ (nommé d’après les trois auteurs précédents + Michael Saks, dans un papier intitulé An Improved Exponential-Time Algorithm for  -SAT) : plutôt que de regarder les clauses une à une pour voir si par hasard on peut éliminer un choix trivialement idiot, on en regarde beaucoup à la fois (typiquement
-SAT) : plutôt que de regarder les clauses une à une pour voir si par hasard on peut éliminer un choix trivialement idiot, on en regarde beaucoup à la fois (typiquement  , où est le nombre de variables de la formule) pour tenter d’en tirer les mêmes conclusions. il y a un nombre sous-exponentiel d’ensembles de clauses, et examiner chacun d’entre eux peut se faire en temps sous-exponentiel aussi (on peut se contenter de regarder toutes les valeurs possible pour le sous-ensemble de variables qui interviennent dans ce sous-ensemble de clauses). Les mauvais choix ne peuvent plus nécessairement être qualifiés de « trivialement idiots » mais peut-être de « manifestement idiots » ; le résultat est le même : si on peut les détecter, autant les éviter. Pour le coup, l’analyse de la probabilité de succès de cet algorithme est (beaucoup) plus complexe ; pour la petite histoire, lorsque l’article original a été publié, les auteurs n’avaient établi la probabilité de succès que dans le cas où la formule n’avait qu’une seule affectation satisfaisante (l’analyse du cas général n’arrivait à prouver qu’une probabilité de succès plus basse). La preuve plus générale a été établie par Timon Hertli (3-SAT Faster and Simpler – Unique-SAT Bounds for PPSZ Hold in General), mais il s’est passé plus de dix ans entre l’introduction de l’algorithme et la preuve en question. Une version « lisible » (pour une certaine définition de « lisible, admettons-le) de la preuve en question est disponible dans ma thèse de semestre (chapitre 2) – elle est difficile à résumer en moins de, mettons, 8 pages (heu, déjà 8 pages, c’est challenge, en fait.)
, où est le nombre de variables de la formule) pour tenter d’en tirer les mêmes conclusions. il y a un nombre sous-exponentiel d’ensembles de clauses, et examiner chacun d’entre eux peut se faire en temps sous-exponentiel aussi (on peut se contenter de regarder toutes les valeurs possible pour le sous-ensemble de variables qui interviennent dans ce sous-ensemble de clauses). Les mauvais choix ne peuvent plus nécessairement être qualifiés de « trivialement idiots » mais peut-être de « manifestement idiots » ; le résultat est le même : si on peut les détecter, autant les éviter. Pour le coup, l’analyse de la probabilité de succès de cet algorithme est (beaucoup) plus complexe ; pour la petite histoire, lorsque l’article original a été publié, les auteurs n’avaient établi la probabilité de succès que dans le cas où la formule n’avait qu’une seule affectation satisfaisante (l’analyse du cas général n’arrivait à prouver qu’une probabilité de succès plus basse). La preuve plus générale a été établie par Timon Hertli (3-SAT Faster and Simpler – Unique-SAT Bounds for PPSZ Hold in General), mais il s’est passé plus de dix ans entre l’introduction de l’algorithme et la preuve en question. Une version « lisible » (pour une certaine définition de « lisible, admettons-le) de la preuve en question est disponible dans ma thèse de semestre (chapitre 2) – elle est difficile à résumer en moins de, mettons, 8 pages (heu, déjà 8 pages, c’est challenge, en fait.)
J’ai travaillé autour de ces algorithmes depuis un an et demi (pas complètement par hasard, Timon dont je parle précédemment étant doctorant à l’ETH… et mon superviseur sur tout ce que j’ai fait), et pour le coup c’est probablement LE sujet sur lequel je me sens prête à répondre à BEAUCOUP de questions 🙂

Bonjour,
Vous repondriez à une question (la publication est d 2014 ?) Algorithme PPZ
Merci et tous mes vœux pour 2020.
Alexis
Alors ça fait un bout de temps que j’ai pas creusé là-dedans et je suis probablement rouillée, mais je peux faire de mon mieux 🙂