J’avais dit que je ferais un billet sur les algorithmes aléatoires, et je ne l’ai toujours pas fait. Une petite part de flemme, et une grosse part d’infusion – mais je viens enfin de trouver l’exemple raisonnablement rigolo et abordable que je cherchais depuis longtemps…
Le principe de l’algorithme aléatoire, c’est essentiellement « boah, on va faire n’importe quoi, et puis si on fait n’importe quoi suffisamment de fois, on finira bien par tomber sur une solution qui marche ». Le « n’importe quoi » consiste à faire un choix au hasard quand on ne sait pas quoi faire, et le « suffisamment de fois » dépend du « n’importe quoi ». L’idée, c’est que quand on fait les choses au hasard, on a normalement au moins une chance, même infime, de tomber sur une solution. Mais si j’ai, par exemple, une chance sur 1000 de tomber sur la solution à mon problème, si j’exécute la même procédure aléatoire indépendamment 1000 fois, j’ai de bonnes chance de tomber sur ce que je veux. Je ne peux pas garantir à 100% que je vais trouver la solution, mais… Tiens, d’ailleurs, quelle est la probabilité que ça marche en faisant 1000 essais ? C’est un petit exercice assez facile, peut-être qu’un petit rappel de probabilités peut être utile (voir la partie 1 et la partie 2)… Je vais tout de même donner la solution. La probabilité que l’algorithme retourne le bon résultat est 0.001. La probabilité qu’après 1000 fois ça ait réussi au moins une fois, c’est 1 – la probabilité que ça ait échoué toutes les fois. La probabilité que ça échoue, c’est 0.999. Comme mes exécutions sont indépendantes, je peux multiplier les probabilités de tous ces essais entre elles : ça fait 0.999^1000, c’est à dire environ 0.368. Donc, la probabilité que ça ait réussi après 1000 essais est de 0.623. Ce qui peut paraître assez faible, ça fait moins de trois chances sur quatre. Mais si je répète, non pas 1000 fois, mais 3000 fois, j’obtiens une probabilité de succès de 1 – 0.999^3000, soit environ 0.95… Et on peut continuer à répéter pour avoir la probabilité de succès que l’on souhaite obtenir, même avec des probabilités de succès initiales très faibles. Si l’algorithme lui-même n’est pas trop violent en terme de calculs, n’importe quel ordinateur est tout à fait capable d’exécuter ça en un temps correct. Et les algorithmes aléatoires peuvent souvent se permettre d’être très simples – plutôt que de calculer un machin compliqué à calculer, pouf, on met une valeur au hasard et on espère que ça marche.
Ça peut paraître un peu fou comme approche, mais comme j’ai essayé de l’expliquer dans le paragraphe qui précède, on peut en fait faire des choses tout à fait rigoureuses dans le domaine. On prend un algorithme, on calcule la probabilité qu’il renvoie une réponse correcte, de là on déduit combien de fois il faudra le répéter pour avoir une probabilité de succès qui convient, et on est content. Et de là, il y a deux grosses difficultés. La première, c’est d’arriver à un algorithme qui ne soit pas complètement débile. Si l’espace de solutions est immense et qu’on se contente de prendre un élément de l’espace de solutions au pif, ça va rarement donner des choses intéressantes. Par contre, si on arrive à avoir une approche semi-intelligente, ça permet souvent d’avoir des algorithmes qui ont une espérance de temps d’exécution meilleure que les algorithmes déterministes pour un problème donné. La deuxième grosse difficulté, c’est parfois de calculer/prouver la probabilité de succès d’un algorithme (ce qui permet d’avoir une idée du nombre de répétitions à prévoir et donc du temps d’exécution). Il y a une troisième difficulté, qui n’est pas vraiment liée directement à l’algorithme aléatoire lui-même. On ne sait pas, à l’heure qu’il est, si l’ajout d’une composante aléatoire permet toujours d’avoir des algorithmes plus performants. Il existe des gens (j’en fais partie en ce moment) qui s’intéressent à la question de savoir si un algorithme aléatoire donné peut être transformé de façon magique en un algorithme déterministe (sans hasard, donc) en gardant des performances équivalentes. Il y a aussi des gens qui s’intéressent à la question générale de savoir si l’aléatoire peut apporter quelque chose, ou si la classe des problèmes qui se résolvent « facilement » avec des éléments aléatoires est la même que celle des problèmes qui se résolvent « facilement » de façon déterministe – pour une certaine définition de facilement. (Notons d’ailleurs que les deux questions n’ont pas le même sens, en dehors de la distinction « un algorithme donné / une classe de problèmes » – dans le premier cas on cherche à avoir les mêmes performances, dans le second cas, on est plus souples et on pourrait par exemple se contenter d’un « si je peux résoudre un problème en temps t avec de l’aléatoire, je peux le résoudre en temps t³ sans aléatoire »).
Après ces longs paragraphes introductifs et vaguement philosophiques, je vais donner un exemple à partir d’un problème connu, celui des 8 reines. Ça rappellera sans doute des choses à ceux qui ont joué à The 7th Guest il y a 20 ans. On suppose qu’on dispose d’un échiquier – donc une grille 8×8 – et de 8 pions qui peuvent se déplacer comme une reine aux échecs, c’est-à-dire en ligne horizontale ou verticale, et en diagonale, d’un nombre arbitraire de cases. On dit que deux reines sont en conflit lorsqu’elles peuvent s’attaquer - c’est-à-dire qu’elles sont sur la même ligne horizontale, verticale ou diagonale. On veut placer huit reines sur l’échiquier de façon à ce qu’aucune d’elles ne soit en conflit avec aucune autre. C’est pas complètement trivial comme problème, comme on peut s’en rendre compte en essayant de le résoudre à la main (ça se fait, mais c’est pas immédiat). Là, le problème reste relativement simple, au sens où la grille reste assez petite. Faire le même genre de choses avec 50 reines sur un échiquier 50×50, il y a de bonnes chances de ne pas s’en sortir à la main. Et puis construire un algorithme déterministe pour ce machin, c’est pénible, ça backtracke dans tous les sens, et moi le backtracking ça me fout mal au crâne (c’est pas complètement vrai, il y a un algorithme récursif qui existe aussi, mais bon). Donc, voyons ce qu’on peut faire de manière aléatoire. Je vais me limiter dans certains cas aux 8 reines, parce que ça fait des nombres « gérables ». Et je vais tricher un peu, je vais dégainer la Wikipedia sur le sujet Problème des huit dames, et je vais affirmer qu’il existe 92 solutions au problème – ça me sera utile pour donner certains nombres.
On peut prendre une approche vraiment bourrine – on numérote les cases de l’échiquier de 1 à 64, on tire huit numéros de 1 à 64, et on place une reine sur chaque case. Si ça marche, ben on a fini ; si ça marche pas, on reprend les reines de l’échiquier et on recommence. La probabilité de succès de cet algorithme, elle est pas bien élevée – il y a 4 426 165 368 manières de choisir 8 chiffres parmi 64, ce qui nous donne une probabilité de succès d’environ 2.07 × 10^-8. C’est peu.
Donc, on regarde d’un peu plus près le problème, et on fait une observation facile : si je veux avoir la moindre chance qu’une solution marche, une chose est sûre, c’est que je n’aurai qu’une seule reine par colonne de mon échiquier. Donc, plutôt que de prendre huit numéros de 1 à 64, je prends, pour chaque reine, un nombre au hasard de 1 à 8, et je place la reine numéro k sur la colonne k et sur la ligne correspondant au nombre qu’on a pris au hasard. C’est sensiblement meilleur – ça correspond à 8^8 = 16 777 216 possibilités, soit une probabilité de succès qui tourne autour de 5.48 × 10^-6. C’est mieux, mais c’est toujours pas top.
On fait alors l’observation facile suivante : je n’aurai aussi qu’une seule reine par ligne de mon échiquier. Bon, d’accord, j’aurais probablement pu faire l’observation en même temps que la précédente, mais faut pas me brusquer, on est dimanche matin et j’ai mangé de la raclette hier soir. Donc, plutôt que de prendre un nombre au hasard de 1 à 8 pour chaque reine, je prends une permutation au hasard (c’est à dire que je prends un nombre de huit chiffres dans lequel tous les chiffres de 1 à 8 apparaissent), et je pose mes reines en fonction de cette permutation (la première reine sur la ligne du premier chiffre, la deuxième sur la ligne du deuxième, et ainsi de suite). Ça améliore encore un peu les choses – il y a 8! = 40 320 permutations possibles, soit une probabilité de succès de 2.28×10^-3, soit 0.02%. Ça commence à rentrer dans la catégorie des machins « faisables »… mais uniquement pour des petites valeurs de la taille de l’échiquier. Si on monte, mettons, ne serait-ce qu’à 16 reines sur un échiquier de 16×16 cases, la séquence OEIS kivabien nous permet d’évaluer la probabilité de succès à 14 772 512/16!, soit environ 7.06×10^-7. Le problème, c’est que la factorielle, là, ben elle est quand même encore très moche.
On peut encore améliorer les choses. Il y a trois sources de conflits pour les reines sur l’échiquier : les lignes horizontales, les lignes verticales, et les diagonales. L’approche par permutations permet de gérer les deux premières, mais y ajouter la gestion des diagonales commence à filer VRAIMENT mal au crâne (on se retrouve à faire des machins du genre « si j’ai deux chiffres qui sont dans des positions qui diffèrent de k, ils ne peuvent pas différer eux-mêmes de k », et c’est imbitable). Par contre, ce qu’on peut faire assez facilement, c’est générer la permutation petit à petit. L’idée, c’est qu’on place les reines une par une au hasard dans une colonne, en supprimant toutes les lignes qui sont en conflit avec une reine placée précédemment. Donc, on place la première reine au hasard sur la première colonne, la deuxième reine au hasard, mais de façon à ce qu’elle ne soit pas sur la ligne de la première ni sur ses diagonales, et ainsi de suite. Et si on ne peut pas trouver une position sans conflit dans la colonne, c’est que la solution courante ne marche pas – on vire tout et on recommence du début. Je n’ai pas trouvé d’analyse rigoureuse de ce machin, et j’ai la flemme de la tenter moi-même (je soupçonne accessoirement ne pas être capable de m’en sortir, du moins pas dans un temps qui me permette de publier ce billet rapidement), mais il y a au moins une implémentation qui a été testée sur 1000 reines avec des temps d’exécution raisonnables (variant apparemment de 39 secondes à 25 minutes). L’idée, cela dit, c’est qu’on élimine beaucoup de permutations de l’espace de recherche : par exemple, on supprime toutes celles qui commencent par « 12 » – ce qui correspond, pour un problème de 8 reines, à 720 permutations, ce qui n’est pas énorme, mais si on multiplie ça par 14 (parce qu’on supprime aussi celles qui commencent par « 23 », « 34 »,…, « 78 », « 21 », « 32 »,…,« 87 »), à 10 080 permutations, soit déjà un quart de l’espace de recherche ! Plus l’échiquier est grand, moins ces deux premières étapes seront significatives (et plus le « un quart » va tendre vers 0, si vous me passez l’expression), mais l’idée reste la même : on réduit l’espace de recherche, et la probabilité de succès augmente.
Toutes ces approches ont la même base : on recherche une combinaison qui fonctionne dans tout l’ensemble des combinaisons, en essayant de supprimer les combinaisons qui ne marchent pas le plus tôt possible. Il existe un autre type d’approche, qui est celle de la « réparation ». L’idée, c’est que pour une permutation donnée, on n’est peut-être pas loin d’une solution qui marche. Donc, plutôt que d’explorer l’espace de combinaisons entier, on peut peut-être explorer autour d’une permutation en essayant de se rapprocher d’une solution. Une solution, par définition, c’est une combinaison qui a zéro conflit. Donc, on peut supposer qu’on se « rapproche » d’une solution quand on diminue le nombre de conflits. C’est l’idée du dernier algorithme que je vais présenter dans ce billet. On commence par prendre une permutation aléatoire qui « a une bonne tête » en utilisant l’algorithme précédent et, au lieu de s’arrêter lorsqu’on rencontre un conflit, en plaçant une reine au hasard sur l’une des cases présentant le nombre minimum de conflits de la colonne. Si elle marche, tant mieux, on a fini. Sinon, on choisit une colonne au hasard, et on compte, pour chaque case, le nombre de conflits auquel elle correspond, en ne comptant qu’un seul conflit si plusieurs reines génèrent ce conflit (parce de toute façon elles sont alors en conflit entre elles, et il faudra gérer ça). S’il existe une case pour laquelle la reine de la colonne courante aurait moins de conflits, on la déplace (en choisissant au hasard la case si plusieurs d’entre elles ont le même nombre de conflits). Et on recommence. Il n’y a en revanche pas de garantie que cet algorithme va toujours renvoyer une solution : si on n’a pas de chance, on peut se retrouver dans un minimum local, ne pouvoir améliorer le nombre de conflits sur aucune colonne, et boucler infiniment. Il faut prendre ce genre de cas en compte, et arrêter/recommencer l’algorithme si le nombre d’étapes commence à exploser vraiment trop violemment. Là, vraiment, je sais que l’analyse de cet algorithme va au-delà de ce que je veux présenter sur ce blog (j’avoue ne pas l’avoir lue, surtout qu’il manque des figures sur le papier). Le papier qui présente la méthode indique que le nombre de conflit réparés reste à peu près constant quel que soit la taille de la grille, et qu’ils arrivent à résoudre le problème sur un échiquier d’un million de cases de côté en 4 minutes. Sur une SPARCstation 1, en 1991.
Bref, les algorithmes aléatoires, c’est rigolo et utile. Je pense qu’un prochain billet discutera des algorithmes aléatoires pour SAT, parce que c’est quand même ce sur quoi je passe beaucoup de temps en ce moment. J’ai quand même passé un truc assez fondamental sous le tapis, c’est que générer des nombres aléatoires, c’est hautement non-trivial. En pratique, ce que j’ai présenté ici fonctionne aussi avec des nombres « à peu près aléatoires » tels qu’un ordinateur est capable de les générer. Mais ceci est une autre histoire, que nous vous raconterons une prochaine fois… ou pas, parce que là, j’ai pas le niveau 😛




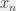





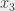





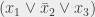
sur
, si
est trivialement idiot, on affecte 1 à
est trivialement idiot, on affecte 0 à




