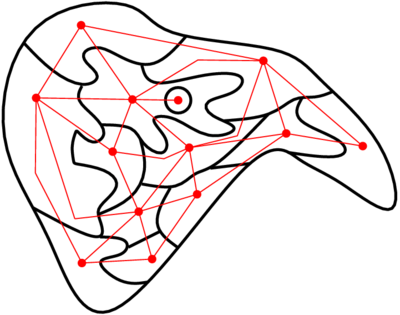
Aujourd’hui, c’est coloriage. Je vais déjà commencer par vous montrer un petit jeu : ça s’appelle Map, c’est tout con : le jeu vous donne une carte rectangulaire avec des zones à colorier, et quelques couleurs déjà placées ; il faut colorier les autres de façon à ce que deux voisins n’aient pas la même couleur. Allez-y, allez jouer un peu avec, c’est rigolo 😛 La question théorique derrière ce petit jeu est la suivante : quel est le nombre minimal de couleurs nécessaires pour pouvoir colorier n’importe quelle carte de ce type ? Peut-être que vous vous souvenez, mais j’ai déjà un peu parlé de problèmes de ce genre là : quand j’ai parlé de P vs NP, j’ai parlé de colorabilité de graphes, et de décider si un graphe donné pouvait être colorié avec un nombre donné de couleurs. La question du nombre minimum de couleurs peut revenir à poser la question précédente plusieurs fois : « et avec 2 couleurs, ça passe ? non ? et avec trois ? non plus ? et avec quatre ? ah, cool. » Là, normalement, j’ai deux objections dans la salle. La première, c’est : « minute papillon, tu parlais de cartes et là tu me parles de graphes, c’est pas pareil, si ? ». La deuxième, c’est « heu, dis voir, demander si un graphe peut être colorié avec trois couleurs, on a vu dans le P vs NP que c’était pas trivial comme question… donc on fait quoi, surtout qu’il y a peut-être beaucoup de nombres à considérer ? ». Il se trouve que la première objection permet de répondre à la deuxième. Pour répondre à la première objection, je vais faire un petit dessin. Voilà le petit dessin. 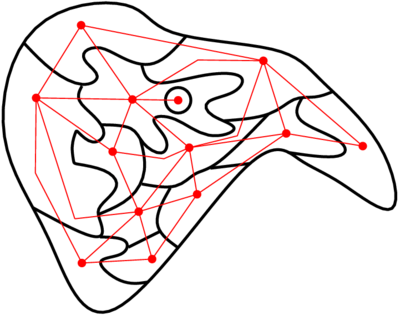 Le petit dessin en question, il est fait comme suit :
Le petit dessin en question, il est fait comme suit :
- j’ai commencé par dessiner la carte – la structure en noir ;
- j’ai ajouté un point dans chaque zone de la carte (les points rouges) ;
- j’ai relié deux points (avec les traits rouges) si les zones correspondantes étaient voisines.
NORMALEMENT j’ai vérifié ma construction, mais si elle est bancale (si j’ai des traits en trop ou en pas assez), merci de me le signaler 🙂 Et là, que voit-on apparaître en rouge sous nos yeux ébahis ? Un graphe. Pas n’importe quel graphe, d’ailleurs : il s’agit d’un graphe planaire, c’est à dire qu’on peut le dessiner sur une feuille de papier sans que deux arcs se croisent. J’ai parlé de graphes planaires dans un billet de blog précédent : Planarité, mineurs et donuts. Là, il va falloir que vous me fassiez confiance sur quelques points. Primo, la construction ci-dessus est toujours possible. Deuzio, ça donne toujours un graphe planaire. Tertio, ce graphe planaire est unique pour une carte donnée : il a toujours le même nombre de sommets, et les arcs sont toujours les mêmes. Et c’est là qu’on répond à la deuxième objection. Oui, dans le cas général, décider si un graphe peut être colorié avec 3, 4, 5 ou 12 couleurs est difficile (au stade actuel de nos connaissances). Par contre, dans le cas particulier des graphes planaires, on sait plus de choses. Plus précisément, on connaît le théorème suivant, appelé « théorème des 4 couleurs » :
Tout graphe planaire peut être colorié avec au maximum 4 couleurs.
Et, comme corollaire au point précédent, je peux colorier une carte avec quatre couleurs (il suffit de faire ma petite construction là-haut, de colorier le graphe résultant, et de colorier chaque zone avec la couleur du sommet en question – rappelons que dans le cas qui nous intéresse, un coloriage est valide si deux sommets reliés par un arc n’ont pas la même couleur.) Un petit aparté: je parle de « cartes » ici, mais c’est pas vraiment applicable directement « dans la vraie vie ». Le problème principal, c’est que certains pays ne sont pas « connectés ». Et si on colorie une carte du monde, on s’attend à ce que, par exemple, la Guyane soit de la même couleur que la France. Ce qui ajoute des arcs entre la zone « France » et les zones « Brésil » et « Suriname », et qui risque fort de nuire à la planarité du graphe correspondant. Fin de l’aparté, revenons à nos moutons. Donc, si j’ai un graphe planaire, je peux répondre directement à la question « est-ce que ce graphe peut être colorié avec k couleurs » par « oui », dès que k est supérieur ou égal à 4. La preuve du théorème des quatre couleurs est… compliquée. J’en parlerai dans un prochain billet, mais il faut que je me documente encore un peu avant sur le sujet 🙂
Un résultat intéressant est que pour trois couleurs, même dans le cas « graphe planaire », le problème reste NP-complet ! (C’est un résultat de Stockmeyer en 1973, dans un article intitulé « Planar 3-colorability is polynomial complete », qui 40 ans plus tard est toujours planqué en tant qu’article payant à l’ACM. Mais je digresse.) Donc, pour 3 couleurs, c’est dur à décider, pour 4 couleurs, on sait qu’on peut le faire, mais c’est dur à prouver. En revanche, le théorème suivant est relativement simple à prouver :
Tout graphe planaire peut être colorié avec au maximum 5 couleurs.
J’ai dit que c’était relativement simple à prouver, et donc je vais le faire. Ça va quand même être probablement un peu long, donc accrochez-vous, et je vais essayer de faire preuve de pédagogie 🙂
J’ai besoin d’un premier résultat pour ma preuve :
Tout graphe planaire contient au moins un sommet de degré au plus 5.
Le degré d’un sommet, c’est le nombre d’arcs qui y sont connectés. Comme un arc connecte exactement deux sommets, si je fais la somme des degrés de tous les sommets, j’obtiens deux fois le nombre d’arcs (parce qu’un arc donné est compté exactement deux fois, une fois à chacune de ses extrémités). Maintenant, je vais vous demander d’admettre encore un truc, c’est qu’on connaît le nombre maximal d’arcs d’un graphe planaire, en fonction de son nombre de sommets, n : il y a au plus 3n-6 arcs, dès qu’il y a plus de deux sommets (comme on me l’a fait remarquer en commentaire). Je pourrais aussi le démontrer, mais ça implique encore un résultat intermédiaire, et ce billet va finir par être vraiment beaucoup trop long (dit-elle au bout de deux pages). Comme j’ai au plus 3n-6 arcs, la somme des degrés de tous les arcs d’un graphe planaire est inférieure ou égale à 6n-12. Par conséquent, il y a au moins un sommet de degré au plus 5 : si ce n’est pas le cas, la somme des degrés de tous les arcs est supérieure ou égale à 6n (6 arcs, multipliés par n sommets), et ce n’est pas possible pour un graphe planaire.
Revenons à nos moutons initiaux : on veut maintenant démontrer que tout graphe planaire peut être colorié avec au maximum 5 couleurs. On va faire un raisonnement par récurrence sur le nombre de sommets du graphe. J’ai interrompu la rédaction de ce billet pour aller faire un billet sur le raisonnement par récurrence, allez le lire si le terme ne vous est pas ou plus clair 🙂 Donc, on commence par traiter l’hypothèse de base. Si mon graphe n’a qu’un seul sommet, je peux le colorier avec au maximum 5 couleurs : j’en choisis une pour mon sommet, et voilà.
Maintenant, je suppose que l’hypothèse de récurrence suivante est vraie : tout graphe planaire à (n-1) sommets peut être colorié avec au maximum 5 couleurs. Le but du jeu est maintenant de déduire, à partir de ça, que tout graphe planaire à n sommets peut être colorié avec au maximum 5 couleurs. Pour ça, on considère un graphe à n sommets, n’importe lequel (si je démontre que ça marche pour n’importe quel graphe, je montre que ça marche pour tous les graphes). Par le résultat intermédiaire que j’ai prouvé au-dessus, le graphe à n sommets étant planaire, il a un sommet de degré inférieur ou égal à 5, qu’on va appeler v dans la suite pour aller vite. On peut prendre v, et le retirer temporairement (on retire aussi tous les arcs qui y sont connectés). Le graphe sans v est un graphe planaire à (n-1) sommets. Donc, on peut le colorier avec au maximum 5 couleurs. Maintenant, on remet v (et les arcs qu’on a retirés aussi) : on obtient un graphe à n sommets dont (n-1) sommets sont coloriés avec au maximum 5 couleurs, et un sommet, v, n’a pas encore de couleur.
Là, on a deux possibilités. Si les voisins de v (les sommets auxquels v est connecté) utilisent moins de 5 couleurs, on peut utiliser une des couleurs non utilisées pour colorier v, et le graphe initial est colorié avec au maximum cinq couleurs.
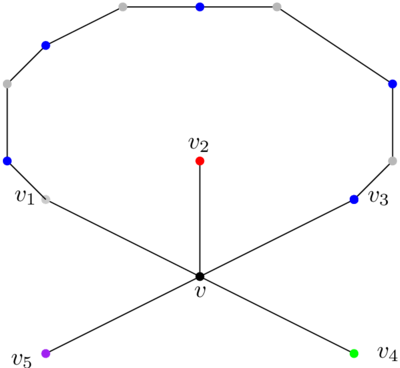
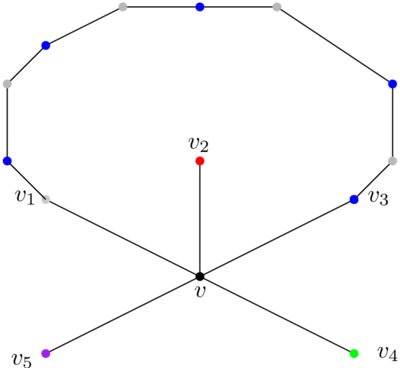
Sinon, si on prend une représentation plane du graphe planaire, on est dans la situation suivante :
 Je n’ai dessiné ici que six sommets, v et ses cinq voisins. Le graphe peut contenir plus de sommets et plus d’arcs, mais il contient forcément cette structure.
Je n’ai dessiné ici que six sommets, v et ses cinq voisins. Le graphe peut contenir plus de sommets et plus d’arcs, mais il contient forcément cette structure.
Sur ma représentation plane, je choisis arbitrairement un voisin de v, je l’appelle v1, et je numérote les autres dans le sens des aiguilles d’une montre (v2 à v5). Les sommets v1 à v5 sont de cinq couleurs différentes. Je vais maintenant prouver que je peux soit colorier v1 et v3 de la même couleur, soit colorier v2 et v4 de la même couleur.
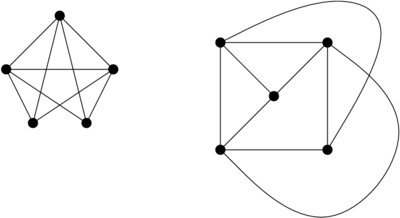
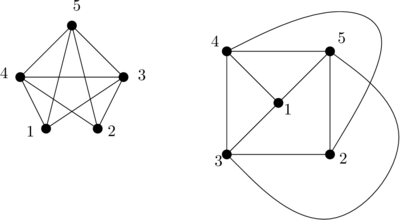
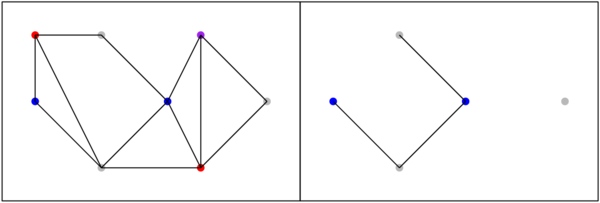
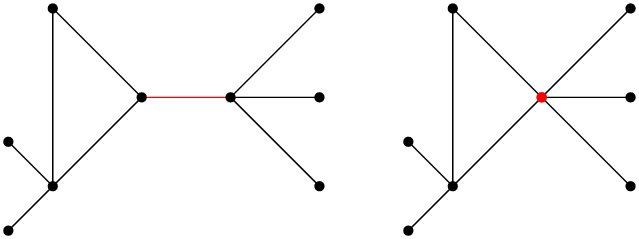
Je regarde d’abord v1 et v3, et plus précisément je m’intéresse au sous-graphe colorié avec les couleurs de v1 et de v3, c’est-à-dire que je prends tous les sommets de la couleur de v1 (gris, sur la figure) et tous les sommets de la couleur de v3 (bleu, sur la figure), et tous les arcs du graphe initial qui relient ces sommets entre eux. Un exemple sur un petit graphe :
 À droite, j’ai représenté le sous-graphe du graphe de gauche en ne prenant que les sommets bleus et gris (j’ai supprimé les sommets rouges et violets, et les arcs qui y étaient attachés). Sur ma figure, j’ai quatre sommets entre lesquels j’ai des chemins (une suite d’arcs qui me permettent de passer de l’un à l’autre), et un sommet qui n’a de chemin vers aucun autre.
À droite, j’ai représenté le sous-graphe du graphe de gauche en ne prenant que les sommets bleus et gris (j’ai supprimé les sommets rouges et violets, et les arcs qui y étaient attachés). Sur ma figure, j’ai quatre sommets entre lesquels j’ai des chemins (une suite d’arcs qui me permettent de passer de l’un à l’autre), et un sommet qui n’a de chemin vers aucun autre.
Si je ne regarde que les sous-graphe bleu/gris de mon graphe initial, j’ai deux possibilités : soit v1 et v3 ne sont plus connectés, soit ils le sont encore ; et par « connectés », j’entends qu’il y a un chemin entre v1 et v3. S’il n’y a pas de chemin, v1 et v3 sont dans des composants différents (un composant, c’est un ensemble de sommets qui sont reliés les uns aux autres par des chemins). Dans ce cas là, je regarde le composant qui contient v3 (il se peut que ce soit v3 tout seul, mais sinon c’est un ensemble de sommets bleus et gris qui ont tous un chemin connecté à v3). Dans ce composant-là, le fait que les sommets soient bleus ou gris est arbitraire : je peux inverser les deux couleurs sans que ça ait un impact sur le fait que le graphe est correctement colorié. Si je ne fais ça que dans ce composant là, v1 (qui n’est pas dans composant en question) reste gris, et v3 (qui était bleu) devient gris. Maintenant, je peux remettre le « reste » du graphe (les sommets rouges, violets, verts, et le sommet v qui n’est pas encore colorié) : comme je n’ajoute pas de sommets bleus ou gris, le coloriage reste valide. Et j’ai « libéré » le bleu pour mon sommet v : donc, je peux colorier v en bleu. La vie est belle.
Enfin, presque. Parce qu’il se peut aussi que v1 et v3 soient dans le même composant « bleu/gris ». Donc là, si j’inverse le bleu et le gris, ben je me retrouve avec v1 en bleu, et v3 en gris, et je peux toujours rien faire avec v. Donc, il faut trouver une autre astuce.
Je regarde maintenant le sous-graphe composé des sommets coloriés avec les couleurs de v2 (rouge) et v4 (vert) : je retire tout ce qui n’est pas rouge ou vert du graphe, et je regarde ce qui reste. Si v2 et v4 ne sont pas dans le même composant rouge/vert, je peux inverser le rouge et le vert dans le composant de v4. v2 reste rouge, v4 devient rouge, et je peux colorier v en vert. Là, j’ai peut-être quelqu’un qui me dit « oui, mais si v2 et v4 sont aussi dans le même composant, tu as le même raisonnement et donc le même problème que pour le composant bleu/gris ! ». Oui, mais. Regardons un peu ce qui se passe sur la figure. Comme v1 et v3 sont dans le même composant bleu/gris (sinon, on n’aurait pas besoin de regarder ce qui se passe dans le composant rouge/vert), il y a un chemin entre v1 et v3 composé de sommets bleus et gris.
Si je veux faire un chemin composé de sommets verts et rouges entre v2 et v4 (ce qui est la condition pour que v2 et v4 soient dans le même composant rouge/vert), ça bloque : soit je dois croiser l’arc entre v et v3, soit je dois croiser un des arcs du chemin bleu/gris entre v1 et v3. Et comme mon graphe est plan… ben j’ai pas de croisement entre mes arcs. Donc, v2 et v4 ne peuvent pas être dans le même composant, donc je peux bien inverser les couleurs du composant de v4, et colorier v en vert.
J’ai donc regardé tous les cas possibles pour mon graphe, et dans tous les cas, je peux colorier le sommet v de façon valide. Donc, si un graphe avec (n-1) sommets peut être colorié avec au maximum 5 couleurs, alors un graphe avec n sommets peut être colorié avec au maximum 5 couleurs, ce qui termine mon étape de récurrence et donc la preuve du théorème des cinq couleurs. Ouf.
J’avais initialement prévu de parler du théorème des 4 couleurs plus en détail dans ce billet, mais je crois que je vais arrêter là pour ne pas fumer plus de neurones de mon lectorat (en espérant qu’il y en ait quand même une partie qui soit arrivée jusqu’ici…). Comme d’habitude, pour les questions, typos, remarques, etc., c’est dans les commentaires que ça se passe 🙂


dans le premier graphe mais pas dans le second (le degré d’un sommet, c’est le nombre d’arcs qui y sont connectés)


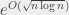
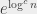




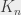 le graphe complet sur n sommets - par exemple, je vous présente
le graphe complet sur n sommets - par exemple, je vous présente  :
:


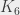 ), comme celui-ci :
), comme celui-ci :
 coloriages différents. Pour voir ça, on peut choisir un ordre pour les arcs (n’importe quel ordre) et commencer à colorier. Pour le premier arc, on peut choisir rouge ou bleu, ça fait deux choix. Pour le deuxième arc, idem – et on a déjà quatre choix avec deux arcs, puisqu’ils peuvent être tous les deux rouges, tous les deux bleus, rouge-bleu ou bleu-rouge. Le troisième choix multiplie encore ces choix par deux (puisque chaque choix peut correspondre à un troisième arc rouge ou bleu), et ainsi de suite pour les 15 arcs, soit 2×2×2×…×2 =
coloriages différents. Pour voir ça, on peut choisir un ordre pour les arcs (n’importe quel ordre) et commencer à colorier. Pour le premier arc, on peut choisir rouge ou bleu, ça fait deux choix. Pour le deuxième arc, idem – et on a déjà quatre choix avec deux arcs, puisqu’ils peuvent être tous les deux rouges, tous les deux bleus, rouge-bleu ou bleu-rouge. Le troisième choix multiplie encore ces choix par deux (puisque chaque choix peut correspondre à un troisième arc rouge ou bleu), et ainsi de suite pour les 15 arcs, soit 2×2×2×…×2 = 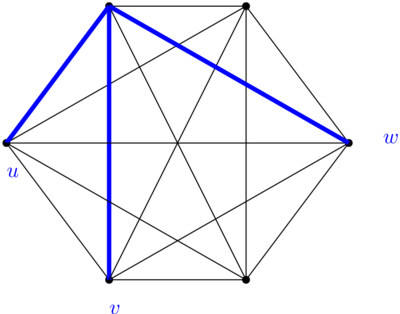
 et
et 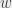 . Et là, il peut se passer plusieurs choses. Si l’arc entre
. Et là, il peut se passer plusieurs choses. Si l’arc entre 
 est tout rouge. Tout ce que j’ai raconté là s’applique à n’importe quel coloriage (même s’il faut éventuellement changer rouge en bleu et bleu en rouge), et donc on ne peut pas trouver de coloriage qui n’ait ni triangle bleu, ni triangle rouge.
est tout rouge. Tout ce que j’ai raconté là s’applique à n’importe quel coloriage (même s’il faut éventuellement changer rouge en bleu et bleu en rouge), et donc on ne peut pas trouver de coloriage qui n’ait ni triangle bleu, ni triangle rouge. , contient une
, contient une 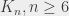 sans triangle monochromatique.
sans triangle monochromatique. , on peut trouver un coloriage tel qu’on ne trouve pas de triangle monochromatique, et pour
, on peut trouver un coloriage tel qu’on ne trouve pas de triangle monochromatique, et pour  ,
, 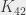 de la même couleur (remarquons qu’un triangle est une
de la même couleur (remarquons qu’un triangle est une  😉 )? Et ben, c’est une question compliquée. Pour être sûr de trouver une
😉 )? Et ben, c’est une question compliquée. Pour être sûr de trouver une 
 (un graphe complet sur 18 sommets, donc) a 153 arcs, donc si on se mettait en tête de vérifier tous les coloriages, il faudrait en vérifier
(un graphe complet sur 18 sommets, donc) a 153 arcs, donc si on se mettait en tête de vérifier tous les coloriages, il faudrait en vérifier  . Si on est capable de vérifier un coloriage par nanoseconde (ce qui n’est pas franchement réaliste), il faudrait plus de 3 000 000 000 000 000 000 000 000 000 (3 suivi de 27 zéros) SIÈCLES pour tout vérifier… on est pas rendu 🙂
. Si on est capable de vérifier un coloriage par nanoseconde (ce qui n’est pas franchement réaliste), il faudrait plus de 3 000 000 000 000 000 000 000 000 000 (3 suivi de 27 zéros) SIÈCLES pour tout vérifier… on est pas rendu 🙂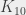 monochromatique, on sait que le seuil se situe quelque part entre 798 (pour 797 sommets on sait qu’on peut colorier sans avoir de
monochromatique, on sait que le seuil se situe quelque part entre 798 (pour 797 sommets on sait qu’on peut colorier sans avoir de  , on peut trouver un
, on peut trouver un 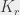 monochromatique. Ledit théorème est plus général que ça : il dit que pour tout
monochromatique. Ledit théorème est plus général que ça : il dit que pour tout  on peut trouver un
on peut trouver un  couleurs
couleurs 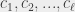 contient ou bien une
contient ou bien une  de couleur
de couleur  , ou bien une
, ou bien une 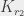 de couleur
de couleur  , …, ou bien une
, …, ou bien une  de couleur
de couleur  . Et on dénote
. Et on dénote  . (Pour rattacher aux trucs précédents, j’ai démontré que
. (Pour rattacher aux trucs précédents, j’ai démontré que  , et j’ai indiqué que
, et j’ai indiqué que  ,
,  et que
et que 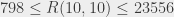 .
.

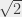 est irrationnel, c’est à dire qu’on ne peut pas l’écrire sous la forme
est irrationnel, c’est à dire qu’on ne peut pas l’écrire sous la forme  avec p et q des nombres entiers.
avec p et q des nombres entiers.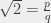 . On peut aussi supposer que la fraction est irréductible, parce que si elle ne l’est pas, on peut la réduire pour qu’elle le soit (rappel : une fraction
. On peut aussi supposer que la fraction est irréductible, parce que si elle ne l’est pas, on peut la réduire pour qu’elle le soit (rappel : une fraction  ). Donc, je peux écrire que
). Donc, je peux écrire que  . Je mets tout au carré, et j’obtiens que 2q² = p². Comme q est entier, q² est entier aussi, et donc p² est pair (puisque c’est deux fois un nombre entier). Mais si p² est pair, alors p est pair aussi, d’après ma preuve auxiliaire. Donc je peux écrire p = 2k, et donc p² = 4k². Mais du coup, comme 2q² = p² = 4k², je peux écrire que q² = 2k², et donc q² est pair, et q est pair. Mais ça, c’est pas possible : la fraction
. Je mets tout au carré, et j’obtiens que 2q² = p². Comme q est entier, q² est entier aussi, et donc p² est pair (puisque c’est deux fois un nombre entier). Mais si p² est pair, alors p est pair aussi, d’après ma preuve auxiliaire. Donc je peux écrire p = 2k, et donc p² = 4k². Mais du coup, comme 2q² = p² = 4k², je peux écrire que q² = 2k², et donc q² est pair, et q est pair. Mais ça, c’est pas possible : la fraction 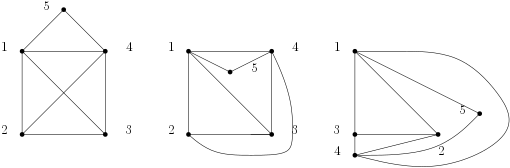
 . En voici des représentations dans le plan ; comme on l’a vu, ces représentations ne sont pas uniques, mais vous pouvez chercher longtemps avant de trouver une représentation où deux arcs ne se croisent pas.
. En voici des représentations dans le plan ; comme on l’a vu, ces représentations ne sont pas uniques, mais vous pouvez chercher longtemps avant de trouver une représentation où deux arcs ne se croisent pas.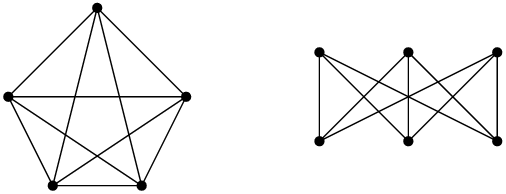

 . Du coup… ben j’ai pas eu le courage, bêtement. La mise en page est immonde, les maths sont illisibles. Je regarde ce truc et j’ai mal au crâne. Un petit morceau de moi se dit que si le type en face n’a pas pris la peine de faire en sorte que son machin soit lisible, je vois pas pourquoi je prendrais la peine de tenter de le lire. Évidemment, c’est hyper-fallacieux, comme argument. Parce que si jamais quelqu’un arrive avec une preuve qui marche, il a moyen de troller une communauté complète rien qu’en publiant sa preuve en Word 😀 Après, je peux argumenter sur le fait que j’ai jamais réussi à utiliser l’éditeur d’équations de Word de façon raisonnablement déterministe, alors que
. Du coup… ben j’ai pas eu le courage, bêtement. La mise en page est immonde, les maths sont illisibles. Je regarde ce truc et j’ai mal au crâne. Un petit morceau de moi se dit que si le type en face n’a pas pris la peine de faire en sorte que son machin soit lisible, je vois pas pourquoi je prendrais la peine de tenter de le lire. Évidemment, c’est hyper-fallacieux, comme argument. Parce que si jamais quelqu’un arrive avec une preuve qui marche, il a moyen de troller une communauté complète rien qu’en publiant sa preuve en Word 😀 Après, je peux argumenter sur le fait que j’ai jamais réussi à utiliser l’éditeur d’équations de Word de façon raisonnablement déterministe, alors que ![\forall i \in \{1,2,3,4,5,6\}, \Pr[X = i] = \frac 1 6](https://s0.wp.com/latex.php?latex=%5Cforall+i+%5Cin+%5C%7B1%2C2%2C3%2C4%2C5%2C6%5C%7D%2C+%5CPr%5BX+%3D+i%5D+%3D+%5Cfrac+1+6&bg=eeeeee&fg=333333&s=0&c=20201002)
![E[X] = \sum_{i} \Pr[X = i] \times i](https://s0.wp.com/latex.php?latex=E%5BX%5D+%3D+%5Csum_%7Bi%7D+%5CPr%5BX+%3D+i%5D+%5Ctimes+i&bg=eeeeee&fg=333333&s=0&c=20201002)
![E[X] = \sum_{i = 1}^6 \Pr[X = i] \times i](https://s0.wp.com/latex.php?latex=E%5BX%5D+%3D+%5Csum_%7Bi+%3D+1%7D%5E6+%5CPr%5BX+%3D+i%5D+%5Ctimes+i&bg=eeeeee&fg=333333&s=0&c=20201002)
![E[X] = 1 \times \Pr[X = 1] + 2 \times \Pr[X = 2] + 3 \times \Pr[X = 3] + 4 \times \Pr[X = 4] + 5 \times \Pr[X = 5] + 6 \times \Pr[X = 6]](https://s0.wp.com/latex.php?latex=E%5BX%5D+%3D+1+%5Ctimes+%5CPr%5BX+%3D+1%5D+%2B+2+%5Ctimes+%5CPr%5BX+%3D+2%5D+%2B+3+%5Ctimes+%5CPr%5BX+%3D+3%5D+%2B+4+%5Ctimes+%5CPr%5BX+%3D+4%5D+%2B+5+%5Ctimes+%5CPr%5BX+%3D+5%5D+%2B+6+%5Ctimes+%5CPr%5BX+%3D+6%5D&bg=eeeeee&fg=333333&s=0&c=20201002)
![E[X] = \frac 1 6 \times (1 + 2 + 3 + 4 + 5 + 6) = \frac{21}{6} = 3.5](https://s0.wp.com/latex.php?latex=E%5BX%5D+%3D+%5Cfrac+1+6+%5Ctimes+%281+%2B+2+%2B+3+%2B+4+%2B+5+%2B+6%29+%3D+%5Cfrac%7B21%7D%7B6%7D+%3D+3.5&bg=eeeeee&fg=333333&s=0&c=20201002)
![E[A + B] = E[A] + E[B]](https://s0.wp.com/latex.php?latex=E%5BA+%2B+B%5D+%3D+E%5BA%5D+%2B+E%5BB%5D&bg=eeeeee&fg=333333&s=0&c=20201002)
![E[A \times B] = E[A] \times E[B]](https://s0.wp.com/latex.php?latex=E%5BA+%5Ctimes+B%5D+%3D+E%5BA%5D+%5Ctimes+E%5BB%5D&bg=eeeeee&fg=333333&s=0&c=20201002) – c’est vrai, en particulier, si les variables aléatoires A et B sont indépendantes, mais ce n’est pas vrai en général. Fin de l’aparté.
– c’est vrai, en particulier, si les variables aléatoires A et B sont indépendantes, mais ce n’est pas vrai en général. Fin de l’aparté. , et on va se débrouiller pour que la variable
, et on va se débrouiller pour que la variable  soit la somme de toutes ces variables. Et pour ça, on définit chaque variable
soit la somme de toutes ces variables. Et pour ça, on définit chaque variable  comme suit : elle a pour domaine {0,1} (c’est-à-dire qu’elle ne peut prendre que la valeur 0 ou 1), et elle a la valeur 1 exactement lorsque le dé numéro 1 a la valeur 6. On définit les valeurs suivantes de la même manière. Puisque j’ai n variables, et qu’elles ont la valeur 1 quand le dé qui leur correspond vaut 6, je peux écrire que
comme suit : elle a pour domaine {0,1} (c’est-à-dire qu’elle ne peut prendre que la valeur 0 ou 1), et elle a la valeur 1 exactement lorsque le dé numéro 1 a la valeur 6. On définit les valeurs suivantes de la même manière. Puisque j’ai n variables, et qu’elles ont la valeur 1 quand le dé qui leur correspond vaut 6, je peux écrire que
![E[Y] = E[\sum_{i=1}^n Y_i] = \sum_{i=1}^n E[Y_i]](https://s0.wp.com/latex.php?latex=E%5BY%5D+%3D+E%5B%5Csum_%7Bi%3D1%7D%5En+Y_i%5D+%3D+%5Csum_%7Bi%3D1%7D%5En+E%5BY_i%5D&bg=eeeeee&fg=333333&s=0&c=20201002)
 , elles sont vachement plus simples. Avec une probabilité 1/6, elles ont la valeur 1, et avec une probabilité 5/6, elles ont la valeur 0 (puisqu’avec une probabilité 1/6, le dé i a la valeur 6). Du coup, l’espérance de
, elles sont vachement plus simples. Avec une probabilité 1/6, elles ont la valeur 1, et avec une probabilité 5/6, elles ont la valeur 0 (puisqu’avec une probabilité 1/6, le dé i a la valeur 6). Du coup, l’espérance de ![E[Y_i] = 1 \times \frac 1 6 + 0 \times \frac 5 6 = \frac 1 6](https://s0.wp.com/latex.php?latex=E%5BY_i%5D+%3D+1+%5Ctimes+%5Cfrac+1+6+%2B+0+%5Ctimes+%5Cfrac+5+6+%3D+%5Cfrac+1+6&bg=eeeeee&fg=333333&s=0&c=20201002)
![E[Y] = \sum_{i=1}^n E[Y_i] = \sum_{i=1}^n \frac 1 6 = \frac 1 6 n](https://s0.wp.com/latex.php?latex=E%5BY%5D+%3D+%5Csum_%7Bi%3D1%7D%5En+E%5BY_i%5D+%3D+%5Csum_%7Bi%3D1%7D%5En+%5Cfrac+1+6+%3D+%5Cfrac+1+6+n&bg=eeeeee&fg=333333&s=0&c=20201002)
