Il y a quelque temps, une soumission à arXiv a fait pas mal de bruit. arXiv, pour ceux qui ne connaissent pas, est une archive d’articles scientifiques – les auteurs y soumettent en général des versions préliminaires d’articles publiés ailleurs. arXiv fait un peu de modération pour éviter le spam et les trucs vraiment délirants, mais, si je comprends bien, tant que ça a à peu près une tronche d’article scientifique dans les domaines gérés par arXiv, ça passe la modération.
Et, donc, le 26 mai, ya un article intitulé A Polynomial Time Algorithm for the Hamilton Circuit Problem, par Xinwen Jiang, qui est apparu sur arXiv. Dans la description de l’article, il y a une petite phrase : « Our result implies NP=P », c’est à dire « Notre résultat implique que P=NP ». Pour un petit rappel sur le problème en question, il se trouve que j’ai causé à ce sujet dans le billet intitulé, fort logiquement, Le problème « P est-il égal à NP ? ».
J’avoue que je ne comprends pas bien pourquoi, spécifiquement, ce papier a fait du bruit. Et par « faire du bruit », j’entends qu’il est passé plusieurs fois sur mon radar, par plusieurs sources différentes. Je ne comprends pas pourquoi, parce que des papiers qui prouvent que P = NP ou que P ≠ NP, il y en a au moins une dizaine par an – voir par exemple The P-versus-NP Page qui vise à tous les recenser. Et qu’on ne fait pas tout un pataquès tous les mois à ce sujet.
C’est bizarre, parce qu’il y a tout un tas de choses qui font que ce papier est peu crédible. Scott Aaronson a écrit des choses sur la crédibilité des articles scientifiques « révolutionnaires » : je citerai ici Ten Signs a Claimed Mathematical Breakthrough is Wrong et Eight Signs A Claimed P is not NP Proof Is Wrong. Aaronson s’intéresse plutôt aux preuves P ≠ NP, mais certains arguments sont aussi valides dans le cas des preuves P = NP.
J’avoue humblement que je n’ai pas lu le papier de Xinwen Jiang. Je ne sais pas non plus si quelqu’un (n’importe qui) a lu le papier de façon sérieuse. Je n’ai trouvé aucun article ou billet de blog disant « la preuve de Xinwen Jiang est fausse et voici pourquoi », ni d’article « meeeeerde, ça marche, son truc ». La discussion la plus fournie que j’ai vu passer est celle de Hacker News dans ce fil de discussion.
Personnellement, la raison principale pour laquelle j’ai abandonné la lecture du papier va sembler extrêmement snob. Mais le papier n’est pas écrit en 
Dans les arguments un demi-chouille plus « sérieux », mais qui touchent toujours au méta : l’auteur est tout seul, et il ne remercie aucun collègue, aucun relecteur. Sur un résultat de cette ampleur, c’est un peu bizarre. Évidemment, le concept de génie solitaire qui résout tout seul un problème qui a échappé à des milliers de chercheurs est extrêmement romantique. Mais il est aussi extrêmement peu crédible.
Troisième point : les références bibliographiques. Il y a 12 références bibliographiques dans cet article. Dix d’entre elles sont des auto-références (l’auteur fait référence à des travaux personnels précédents). La première de la liste est un bouquin très classique, genre bouquin de cours sur le sujet. Là encore, c’est douteux.
Pour finir, l’article se termine par « Until now, since 2010.10.06, more than 52 millions of instances have been generated randomly, each of which has 100 vertices. Some instances contain a simple path while others (it is the majority in all the generated instances) do not. All the results show that our polynomial time algorithm can get the same answer as the backtracking algorithm does. No exception. », ce qui se traduit par « Jusqu’à présent, depuis le 6 juin 2010, nous avons généré aléatoirement plus de 52 millions d’instances sur 100 sommets chacunes. Certaines instances contiennent un chemin simple tandis que d’autres (la majorité des instances générées) non. Tous les résultats montrent que notre algorithme polynomial ont le même résultat que l’algorithme de backtracking. Aucune exception. ». Ça pourrait sembler être un argument en faveur de la preuve. Mais il y a plusieurs choses qui sont discutables sur cet argument. Déjà, il se peut que le générateur aléatoire d’instances soit biaisé, et se trouve louper les instances pour lesquelles ça ne marche pas. D’autre part, le nombre de sommets considéré est relativement bas. Si ça se trouve, ça plante pour 1000 sommets. Ou pour 101. Tertio, il se peut que les instances « difficiles » du problème soient rares. Ça fait partie des choses qu’on ne sait pas, d’ailleurs : si P ≠ NP, les instances d’un problème NP donné pour lesquelles c’est effectivement un facteur (c’est-à-dire qui n’ont pas de caractéristique permettant de résoudre l’instance par un algorithme rapide) sont-elles rares ou fréquentes ? Quatro, l’argument « ça fait un moment que je cherche et j’ai toujours pas trouvé de truc qui fait que ça marche pas »… j’ai essayé, hein, ben souvent les gens qui corrigent mes copies sont pas pour 😀
Bref, comme dit précédemment, c’est un peu des arguments fallacieux, tout ça, parce que ça serait facile de transformer n’importe quel papier « crédible » en papier « absolument pas crédible », et là j’aurai l’air très très bête. Je ne sais pas exactement ce que je veux dire, en fait. Dans un sens, ça me gène de recourir à ce genre d’argument pour décider que « ça sent pas bon, son truc », parce qu’il y a toujours le doute, dans un coin de neurone, du « oui, mais si les apparences étaient trompeuses ? ». D’un autre côté, comme dit Aaronson, il y a suffisamment de papiers sur le sujet pour que des heuristiques de crédibilité soient nécessaires. Quelque part, c’est peut-être à relier au processus de recrutement d’un candidat. Un candidat à un job doit souvent passer par des « formes obligées » qui démontrent sa crédibilité. Et il y a probablement un certain nombre de « faux négatifs » dans tout ce processus de formes obligées. On peut le déplorer. Et, dans le cas d’une preuve P = NP, un faux négatif serait… intéressant 😀
Mais dans le cas d’une preuve P = NP, je soupçonne qu’il faille redoubler d’attention à la crédibilité du papier. L’immense majorité de la communauté scientifique est raisonnablement convaincue que P ≠ NP. Du coup, arriver en affirmant l’inverse… ben ça part pas bien, déjà. Et si « le méta pue », il y a peu de chance que quiconque prenne la peine d’examiner le papier.
Et peut-être que demain je vais me prendre une grosse baffe dans la figure parce qu’un papier dont « le méta pue » va démontrer correctement un résultat que personne n’attend. Je crois que P ≠ NP. Et quand je dis « je crois », c’est vraiment exactement ça : une croyance, peut-être même une foi. N’empêche que j’adorerais avoir tort. Ça serait profondément drôle.. Si ça se trouve, on va trouver demain un algorithme pour SAT en n¹⁰⁰⁰⁰. Ben on sera bien avancés avec ça. Les années qui suivront seraient probablement super marrantes – parce que probablement on se tirerait tous la bourre pour faire descendre ce fichu 10000, et ça finirait probablement par arriver. Ça serait marrant.
![\forall i \in \{1,2,3,4,5,6\}, \Pr[X = i] = \frac 1 6](https://s0.wp.com/latex.php?latex=%5Cforall+i+%5Cin+%5C%7B1%2C2%2C3%2C4%2C5%2C6%5C%7D%2C+%5CPr%5BX+%3D+i%5D+%3D+%5Cfrac+1+6&bg=eeeeee&fg=333333&s=0&c=20201002)
![E[X] = \sum_{i} \Pr[X = i] \times i](https://s0.wp.com/latex.php?latex=E%5BX%5D+%3D+%5Csum_%7Bi%7D+%5CPr%5BX+%3D+i%5D+%5Ctimes+i&bg=eeeeee&fg=333333&s=0&c=20201002)
![E[X] = \sum_{i = 1}^6 \Pr[X = i] \times i](https://s0.wp.com/latex.php?latex=E%5BX%5D+%3D+%5Csum_%7Bi+%3D+1%7D%5E6+%5CPr%5BX+%3D+i%5D+%5Ctimes+i&bg=eeeeee&fg=333333&s=0&c=20201002)
![E[X] = 1 \times \Pr[X = 1] + 2 \times \Pr[X = 2] + 3 \times \Pr[X = 3] + 4 \times \Pr[X = 4] + 5 \times \Pr[X = 5] + 6 \times \Pr[X = 6]](https://s0.wp.com/latex.php?latex=E%5BX%5D+%3D+1+%5Ctimes+%5CPr%5BX+%3D+1%5D+%2B+2+%5Ctimes+%5CPr%5BX+%3D+2%5D+%2B+3+%5Ctimes+%5CPr%5BX+%3D+3%5D+%2B+4+%5Ctimes+%5CPr%5BX+%3D+4%5D+%2B+5+%5Ctimes+%5CPr%5BX+%3D+5%5D+%2B+6+%5Ctimes+%5CPr%5BX+%3D+6%5D&bg=eeeeee&fg=333333&s=0&c=20201002)
![E[X] = \frac 1 6 \times (1 + 2 + 3 + 4 + 5 + 6) = \frac{21}{6} = 3.5](https://s0.wp.com/latex.php?latex=E%5BX%5D+%3D+%5Cfrac+1+6+%5Ctimes+%281+%2B+2+%2B+3+%2B+4+%2B+5+%2B+6%29+%3D+%5Cfrac%7B21%7D%7B6%7D+%3D+3.5&bg=eeeeee&fg=333333&s=0&c=20201002)
![E[A + B] = E[A] + E[B]](https://s0.wp.com/latex.php?latex=E%5BA+%2B+B%5D+%3D+E%5BA%5D+%2B+E%5BB%5D&bg=eeeeee&fg=333333&s=0&c=20201002)
![E[A \times B] = E[A] \times E[B]](https://s0.wp.com/latex.php?latex=E%5BA+%5Ctimes+B%5D+%3D+E%5BA%5D+%5Ctimes+E%5BB%5D&bg=eeeeee&fg=333333&s=0&c=20201002) – c’est vrai, en particulier, si les variables aléatoires A et B sont indépendantes, mais ce n’est pas vrai en général. Fin de l’aparté.
– c’est vrai, en particulier, si les variables aléatoires A et B sont indépendantes, mais ce n’est pas vrai en général. Fin de l’aparté. , et on va se débrouiller pour que la variable
, et on va se débrouiller pour que la variable  soit la somme de toutes ces variables. Et pour ça, on définit chaque variable
soit la somme de toutes ces variables. Et pour ça, on définit chaque variable 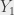 comme suit : elle a pour domaine {0,1} (c’est-à-dire qu’elle ne peut prendre que la valeur 0 ou 1), et elle a la valeur 1 exactement lorsque le dé numéro 1 a la valeur 6. On définit les valeurs suivantes de la même manière. Puisque j’ai n variables, et qu’elles ont la valeur 1 quand le dé qui leur correspond vaut 6, je peux écrire que
comme suit : elle a pour domaine {0,1} (c’est-à-dire qu’elle ne peut prendre que la valeur 0 ou 1), et elle a la valeur 1 exactement lorsque le dé numéro 1 a la valeur 6. On définit les valeurs suivantes de la même manière. Puisque j’ai n variables, et qu’elles ont la valeur 1 quand le dé qui leur correspond vaut 6, je peux écrire que
![E[Y] = E[\sum_{i=1}^n Y_i] = \sum_{i=1}^n E[Y_i]](https://s0.wp.com/latex.php?latex=E%5BY%5D+%3D+E%5B%5Csum_%7Bi%3D1%7D%5En+Y_i%5D+%3D+%5Csum_%7Bi%3D1%7D%5En+E%5BY_i%5D&bg=eeeeee&fg=333333&s=0&c=20201002)
 , elles sont vachement plus simples. Avec une probabilité 1/6, elles ont la valeur 1, et avec une probabilité 5/6, elles ont la valeur 0 (puisqu’avec une probabilité 1/6, le dé i a la valeur 6). Du coup, l’espérance de
, elles sont vachement plus simples. Avec une probabilité 1/6, elles ont la valeur 1, et avec une probabilité 5/6, elles ont la valeur 0 (puisqu’avec une probabilité 1/6, le dé i a la valeur 6). Du coup, l’espérance de ![E[Y_i] = 1 \times \frac 1 6 + 0 \times \frac 5 6 = \frac 1 6](https://s0.wp.com/latex.php?latex=E%5BY_i%5D+%3D+1+%5Ctimes+%5Cfrac+1+6+%2B+0+%5Ctimes+%5Cfrac+5+6+%3D+%5Cfrac+1+6&bg=eeeeee&fg=333333&s=0&c=20201002)
![E[Y] = \sum_{i=1}^n E[Y_i] = \sum_{i=1}^n \frac 1 6 = \frac 1 6 n](https://s0.wp.com/latex.php?latex=E%5BY%5D+%3D+%5Csum_%7Bi%3D1%7D%5En+E%5BY_i%5D+%3D+%5Csum_%7Bi%3D1%7D%5En+%5Cfrac+1+6+%3D+%5Cfrac+1+6+n&bg=eeeeee&fg=333333&s=0&c=20201002)
