Bon, je crois que j’ai tout ce qu’il me faut maintenant que j’ai parlé un petit peu de complexité (partie 1 et partie 2) pour attaquer un morceau sympa, qui est d’expliquer ce qu’il y a derrière la question « P est-il égal à NP ? », que je vais abréger par « P = NP » (de façon assez ironique, on verra pourquoi plus tard). C’est vendredi, vous aurez le week-end pour lire (et peut-être un peu plus parce que je retourne en cours lundi 😉 ).
Le problème P = NP est un des problèmes ouverts (c’est-à-dire non résolu) les plus célèbres, sinon le plus célèbre. Il fait d’ailleurs partie des problèmes du prix du millénaire, une série de 7 problèmes énoncés en 2000 et dont la résolution correcte permettrait à son auteur de toucher un million de dollars. Un seul de ces 7 problèmes a été résolu, la conjecture de Poincaré ; Grigori Perelman l’a démontrée, ce qui lui a valu la médaille Fields (c’est l’équivalent du Nobel pour les maths) et, donc, le million de dollars en question ; il a refusé les deux.
Bon, assez de contexte, maintenant parlons de la bête. P et NP sont ce qu’on appelle des « classes de complexité ». Les classes de complexité sont des ensembles de problèmes qui ont des propriétés communes. L’idée, c’est de prendre des problèmes (par exemple : « est-ce que je peux aller d’un point A à un point B sur mon graphe en moins de 15 étapes ? ») et de les ranger dans des petites cases en fonction de leurs propriétés, en particulier de leur complexité en temps (le temps qu’il faut pour les résoudre) et en espace (la quantité de mémoire qu’il faut pour les résoudre). On s’intéresse ici à la complexité « dans le pire des cas ».
J’ai expliqué dans les billets sur la complexité algorithmique ce que ça voulait dire pour un algorithme de s’exécuter dans un temps donné. Dire qu’un problème se résout en un temps donné, c’est dire qu’on sait le résoudre dans ce temps, c’est-à-dire qu’on a un algorithme qui s’exécute dans ce temps et qui renvoie la bonne solution. Pour reprendre les exemples précédents, on a vu qu’on pouvait trier un ensemble d’éléments (livres… ou autres) en temps n² et en temps n log n. Il se trouve que, dans les modèles de calcul classiques, on ne peut pas faire « mieux » que ce n log n (c’est prouvé). On dit que la complexité du tri est n log n, et on peut dire qu’on peut trier des éléments en temps polynomial.
Un algorithme en temps polynomial est un algorithme qui se termine en un nombre d’étapes inférieur à 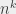 , avec n représentant la taille de l’entrée, et k représentant un nombre quelconque (y compris de très grands nombres, tant qu’ils ne dépendent pas de n lui-même). Le nom vient du fait que les fonctions de type
, avec n représentant la taille de l’entrée, et k représentant un nombre quelconque (y compris de très grands nombres, tant qu’ils ne dépendent pas de n lui-même). Le nom vient du fait que les fonctions de type  ,
,  ,
,  et
et  s’appellent des fonctions polynomiales. Comme je peux trier des éléments en temps n² (et même n log n, ce qui est « mieux »), le tri est résolu en temps polynomial. Ça marcherait aussi si je pouvais trier des éléments en temps n⁴⁷⁹, ça serait aussi polynomial. L’énorme avantage des polynômes, c’est que ça se combine vachement bien. Si je fais deux opérations polynomiales, je reste en temps polynomial. Si je fais un nombre polynomial d’opérations polynomiales, je reste en temps polynomial. Mon polynôme « grossit » (il passe par exemple de n² à n⁵), mais il reste un polynôme.
s’appellent des fonctions polynomiales. Comme je peux trier des éléments en temps n² (et même n log n, ce qui est « mieux »), le tri est résolu en temps polynomial. Ça marcherait aussi si je pouvais trier des éléments en temps n⁴⁷⁹, ça serait aussi polynomial. L’énorme avantage des polynômes, c’est que ça se combine vachement bien. Si je fais deux opérations polynomiales, je reste en temps polynomial. Si je fais un nombre polynomial d’opérations polynomiales, je reste en temps polynomial. Mon polynôme « grossit » (il passe par exemple de n² à n⁵), mais il reste un polynôme.
Bon, et là il va falloir que j’explique la différence entre problème et instance du problème, sinon je vais dire des bêtises (et j’aime pas dire des bêtises). En gros, un problème regroupe toutes les instances d’un problème. Si je dis « je veux trier ma bibliothèque », c’est une instance du problème « je veux trier une bibliothèque quelconque ». Si je m’intéresse au plus court chemin entre deux points sur un graphe donné (par exemple la carte du métro), c’est une instance du problème « plus court chemin dans un graphe », où on considère tous les graphes arbitraires de taille également arbitraire. Le problème est le « concept général », l’instance est « un exemple concret du problème général ».
La classe de complexité P regroupe tous les problèmes dits « de décision » qu’on peut résoudre en temps polynomial. Un problème de décision, c’est un problème qui appelle une réponse de type oui/non. Ça peut paraître une restriction énorme ; en pratique, pas tant que ça. Plutôt que de demander le « plus court chemin », on peut par exemple demander s’il existe « un chemin de distance inférieur à X », et faire varier X jusqu’à trouver le X « limite ». On peut faire ça avec un nombre de requêtes polynomial, donc, si on peut résoudre le problème de décision en temps polynomial, on peut aussi résoudre le problème « numérique » en temps polynomial (Je simplifie salement ici, je crois que ça ne serait pas vrai en général et qu’il me faut des conditions supplémentaires pour que ça marche.) Et une instance de ce problème décisionnel de taille de chemins, ça peut par exemple être « considérant la carte du métro parisien, existe-t-il un chemin allant le La Motte Piquet Grenelle à Belleville en moins de 20 stations, sans prendre en compte les correspondances » (la réponse est oui) ou « en moins de 10 stations » (j’ai pas vérifié complètement, mais je crois que la réponse est non).
Un autre « type » de problème de décision est celui qui regroupe les problèmes de colorabilité de graphes. J’aime bien ce genre d’exemple parce que je peux faire des petits dessins et c’est, je crois, facile à expliquer 🙂 (Bon, c’est pas très daltonien-friendly par contre. Si ya des daltoniens, râlez, je referai les figures avec des numéros pour les couleurs, mais là j’ai la flemme.) On prend un graphe, c’est-à-dire un ensemble de sommets reliés par des arcs, et on veut colorier les sommets de façon à ce que deux sommets n’aient pas la même couleur s’ils sont reliés par un arc. Les questions de colorabilité sont des questions de type « est-ce que je peux colorer mon graphe avec 2, 3, 5, 12 couleurs ». Le problème « non-décisionnel » est celui qui demande quel est le nombre minimal de couleurs nécessaires pour colorer le graphe avec la contrainte exprimée ci-dessus.
Bon, quelques exemples – des instances du problème, donc 🙂
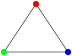
Un graphe « triangle » (trois sommets reliés par trois arcs) ne peut pas être coloré avec seulement deux couleurs, il m’en faut 3 :
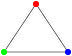
Par contre, un graphe « carré » (trois sommets reliés en carré par quatre arcs) peut être coloré avec deux couleurs seulement :

Je peux avoir des graphes avec un nombre de sommets (et d’arcs) très élevé qui peuvent être colorés avec deux couleurs seulement, pour autant qu’ils suivent ce genre de structure :

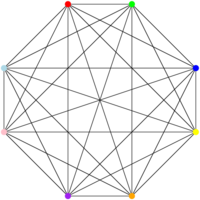
Et je peux avoir des graphes qui demandent un grand nombre de couleurs – une par sommet ! – si tous les sommets sont reliés les uns aux autres, comme sur celui-ci :
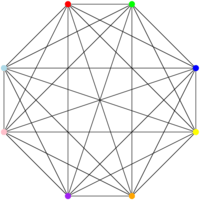
Bon, et c’est là que ça devient intéressant (à mon avis). On sait répondre en temps polynomial à la question « est-ce que ce graphe est colorable avec deux couleurs ? » pour n’importe quel graphe (le « polynomial » ici est en fonction du nombre de sommets du graphe). Pour décider ça, on commence par colorer un sommet, n’importe lequel, du graphe, en bleu. On colorie tous ses voisins, c’est-à-dire tous les sommets qui lui sont reliés par un arc, en rouge (parce que vu que le premier est bleu, tous ses voisins doivent être rouges, sinon on contredit la contrainte qu’on a définie). On essaye de colorier tous les voisins des sommets rouges en bleu, et ainsi de suite. Si on arrive à tout colorier avec cet algorithme, le graphe peut être coloré avec deux couleurs (parce qu’on vient précisément de le faire !). Sinon, c’est qu’un sommet a une contrainte qui l’oblige à être rouge (un voisin bleu) et une contrainte qui l’oblige à être bleu (un voisin rouge). C’est pas complètement évident de voir que ça veut dire que le graphe ne peut pas être coloré avec deux couleurs, mais il se trouve que c’est le cas. L’algorithme se contente, en gros, de parcourir tous les sommets dans un certain ordre et de colorer au fur et à mesure ; on ne visite les sommets qu’une fois ; on vérifie au pire tous les autres sommets (s’ils sont tous connectés) avant de colorier ; si pour chaque sommet je fais au pire une comparaison pour tous les autres sommets et que j’ai n sommets, je pense qu’on peut se convaincre, sans rentrer dans les détails, qu’on fait au pire n*(n-1) opérations, et que l’algorithme est polynomial. (Je ne rentre pas dans les détails ici parce que ça dériverait vilement du sujet ; mais si vous voulez plus de détails, râlez en commentaire et j’essaierai de développer plus).
Par contre, pour la question « est-ce que le graphe est colorable avec trois couleurs ? », ben… on n’a pas encore trouvé d’algorithme en temps polynomial pour répondre à la question pour n’importe quelle instance du problème, c’est à dire pour n’importe quel graphe. Et, pour des raisons que je vais expliquer, genre, dans un prochain billet, si vous trouvez un algorithme (correct !) qui permette de répondre à la question en temps polynomial, il y a de bonnes chances que ça vous fasse gagner une certaine célébrité, possiblement une certaine haine de la part des gens qui font de la cryptographie, et un million de dollars. Intéressant, non ?
L’autre truc intéressant, c’est que si je vous donne un graphe déjà coloré, et que je vous dit « j’ai coloré ce graphe avec 3 couleurs », vous pouvez vérifier, en temps polynomial aussi, que je n’essaie pas de vous enfumer. Il suffit de regarder tous les arcs l’un après l’autre et de vérifier que les deux sommets de l’arc sont colorés avec des couleurs différentes. Facile. Et polynomial.
Ce genre de problème « facilement vérifiable » constitue la classe de complexité NP. Sans partir dans la définition formelle, voilà une idée du machin : un problème décisionnel fait partie de la classe NP si, pour toutes les instances auxquelles je peux répondre « oui », j’ai une « preuve » qui me permet de le vérifier en temps polynomial. Cette « preuve » me permet, en quelque sorte, de répondre à l’interjection « même pas cap ! », ce à quoi je réponds, dans le cas de la colorabilité, par « ben si, tu vois, si je colore comme ça, ça marche, ça prouve bien que je peux le faire avec trois couleurs ». Notez ici que je ne dis rien sur ce qu’il se passe quand je dois répondre « non » à l’instance. Une des raisons, c’est que c’est souvent « plus difficile » de prouver qu’un truc n’est pas faisable que de prouver qu’il l’est. Je peux prouver qu’un truc est faisable en le faisant ; si j’arrive pas à faire un truc, tout ce que ça prouve c’est que j’arrive pas à le faire.
Donc, pour récapituler :
- P est la classe des problèmes auxquels j’arrive à répondre par « oui » ou par « non » en temps polynomial
- NP est la classe des problèmes pour lesquels, pour chaque instance de type « oui », on peut me convaincre en temps polynomial que la réponse est « oui » en me fournissant une preuve que c’est effectivement le cas.
La remarque suivante, c’est que les problèmes qui sont dans P sont aussi dans NP, parce que si j’arrive à répondre moi-même à la question « oui » ou « non » en temps polynomial, je peux être convaincue en temps polynomial que la réponse est « oui » si c’est effectivement le cas (il me suffit d’exécuter l’algorithme polynomial qui me répond « oui » ou « non », et de vérifier qu’il répond « oui »).
La question à, littéralement, un million de dollars, c’est de savoir si tous les problèmes qui sont dans NP sont aussi dans P. Informellement, est-ce que le fait de pouvoir « voir facilement » (c’est à dire en temps polynomial) si un problème a une réponse « oui », pour peu qu’on me fournisse une preuve, veut aussi dire qu’on peut le « résoudre facilement ». Si c’est le cas, alors tous les problèmes de P sont dans NP, tous les problèmes de NP sont dans P, et donc la classe P et la classe NP contiennent exactement les mêmes problèmes, c’est à dire P = NP. Si ce n’est pas le cas, alors il y a des problèmes de NP qui ne sont pas dans P, et donc P ≠ NP.
L’immense majorité des gens qui font des maths pensent que P ≠ NP, mais personne n’a encore réussi à le prouver. Et beaucoup de gens ont essayé 🙂
Ça serait très, très, très surprenant pour tout le monde qu’on arrive à prouver que P = NP. Ça aurait probablement de grosses conséquences, parce que ça indiquerait qu’on a une chance de résoudre des problèmes actuellement considérés comme « difficiles » dans des temps « acceptables ». Une bonne partie de la cryptographie actuelle se base sur le fait non pas qu’il est « impossible » de faire certaines opérations, mais que c’est « difficile » de les faire, c’est à dire qu’on ne connaît pas d’algorithme rapide pour les faire. Ça ne casserait probablement pas immédiatement tout (parce que ça serait probablement difficile à appliquer directement et que ça prendrait du temps), mais il faudrait sans doute se dépêcher de trouver autre chose avant que ça arrive.
Et le dernier truc rigolo, c’est que pour prouver que P = NP, il « suffit » de trouver un algorithme en temps polynomial pour un des problèmes dits « NP-complets » – ce dont je parlerai dans un prochain billet, parce que celui-ci commence à tirer en longueur. La colorabilité à trois couleurs fait partie de ces problèmes NP-complets.
Personnellement, je trouve ça absolument fascinant qu’un problème aussi « facile » à conceptualiser ait de telles implications quant à sa résolution. Et j’espère qu’après avoir lu ce que je viens d’écrire, vous pouvez au moins comprendre ma fascination, à défaut peut-être de la partager 😉
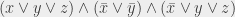



, sinon
(
prend la valeur inverse de x)
; si y = 1 alors
(« x OU y vaut 1 »). Il faut préciser que quand on dit « ou » dans ce contexte, ce n’est pas dans le même sens que « fromage ou dessert » : si on prend du fromage et du dessert, alors on prend du fromage ou du dessert (puisqu’on prend au moins l’un des deux).
, sinon
(« x ET y valent tous les deux 1 »).





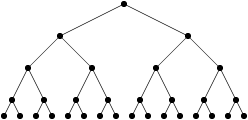
 , où
, où  (et se lit « deux à la puissance
(et se lit « deux à la puissance 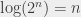

 . Et, bon, ben de la même manière, je peux définir un logarithme qui soit la réciproque de ce
. Et, bon, ben de la même manière, je peux définir un logarithme qui soit la réciproque de ce 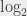 ,
, 
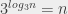

 ,
,  (parce que
(parce que  ); tous les nombres entre 10 et 100 ont un logarithme en base 10 entre 1 et 2. De la même manière, on peut estimer que le logarithme en base 10 de 14578 est entre 4 et 5. Pour voir ça, il suffit de voir que 14578 est compris entre
); tous les nombres entre 10 et 100 ont un logarithme en base 10 entre 1 et 2. De la même manière, on peut estimer que le logarithme en base 10 de 14578 est entre 4 et 5. Pour voir ça, il suffit de voir que 14578 est compris entre  et
et  , ce qui permet de conclure sur la valeur du logarithme. (Je passe un certain nombre de choses sous le tapis ici, en particulier les raisons qui font qu’on peut effectivement conclure ça.)
, ce qui permet de conclure sur la valeur du logarithme. (Je passe un certain nombre de choses sous le tapis ici, en particulier les raisons qui font qu’on peut effectivement conclure ça.) (qui correspond à la puissance à laquelle j’élève
(qui correspond à la puissance à laquelle j’élève 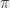 (qui correspond à… bon, ça ira, peut-être) si ça me chante. C’est moins « intuitif » si je considère mon explication avec les arbres et le nombre de niveaux (parce que c’est difficile de faire
(qui correspond à… bon, ça ira, peut-être) si ça me chante. C’est moins « intuitif » si je considère mon explication avec les arbres et le nombre de niveaux (parce que c’est difficile de faire  . Le logarithme népérien est un logarithme en base
. Le logarithme népérien est un logarithme en base  . On peut exprimer n’importe quel logarithme dans n’importe quelle base
. On peut exprimer n’importe quel logarithme dans n’importe quelle base  comme ceci :
comme ceci :
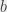 comme ça :
comme ça :

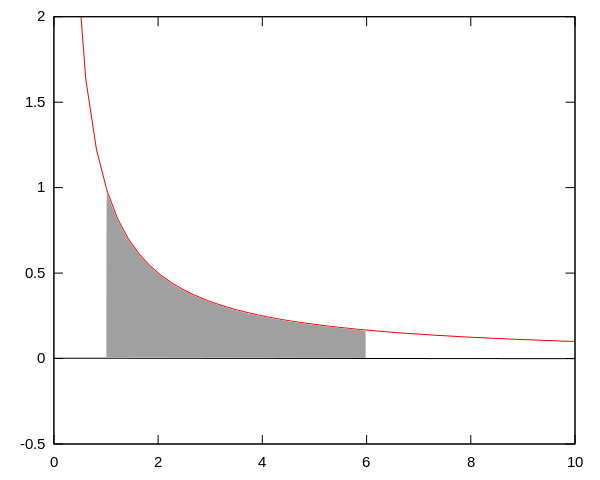
 . La zone grise correspond ici à l’intégrale de 1 à 6 ; l’aire de cette zone est égale à ln(6). Et on peut représenter le logarithme népérien de n’importe quelle valeur (supérieure à 1) par l’aire de la surface située entre l’axe des
. La zone grise correspond ici à l’intégrale de 1 à 6 ; l’aire de cette zone est égale à ln(6). Et on peut représenter le logarithme népérien de n’importe quelle valeur (supérieure à 1) par l’aire de la surface située entre l’axe des  et la courbe
et la courbe 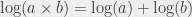




{kind=link}
{kind=link}